intro1:如何设计一个百万QPS的基于用户uid唯一性检验的系统?
intro2: bloomfilter和bitmap和roaringbitmap选型比较
intro3: setbit注意事项
设计要点
这个问题或许会被经常问到,比如抢红包或者秒杀等场景时,限制用户只能领取/抢购一次,也是笔者可能会遇到类似问题,这里有两个关键点:
1,支持64位long型
大部分人可能想到使用Java或Redis提供的bitmap操作,即一个大的bit数组,对应下标标记1来表示用户已经操作过,这样对于32位int来说,需要2^32/8=512MB的内存空间就很容易实现唯一性检查了,但实际上相信大部分系统已经不会使用32位整数表示用户uid了,更多可能使用基于Twitter开源的分布式ID生成算法-Snowflake(当然了,也可能是美团leaf、百度UidGenerator等snowflake的参考时限),这类算法结果是一个long型的数,即这类64bit的数是无法直接用bitmap实现的(512MB*2^31)。
针对该情况bitmap是否依旧可用?
要看具体情况,实际上基于snowflake生成的分布式id虽然在1-2^64之间,但用bitmap存储时却可能是非常稀疏的,我们自然想到去压缩bitmap,本文会介绍下压缩的bitmap即 RoaringBitmap,同时也提供另外一种BloomFilter(下文简称BF)的方案,如果你对二者都熟悉可掠过。
2,支持百万QPS
显然前置条件是需要一种存储,该存储能记录已满足条件的uid,同时支持百万QPS。
如果是纯粹基于同实例(机器)内存,完全是可以做到的,比如对于Java应用来说,不论基于堆内或堆外内存来说如Ehcache、Guava Cache、MapDB以及Spring 5之后采用的Caffeine他们都可轻易做到百万QPS,最简单的内置bitmap单机就能百万QPS,但通常不会只用一份单机数据,否则系统的容错性太差了,分布式存储是一种选择,比如基于Java的分布式内存/存储实现如Hazelcast、Chronicle,不过前者无bitmap实现,Chronicle原生支持byte数组,但如果论成熟度/可靠性,Redis或许是一个不错的选择,redis本身也支持bitmap。
不过Redis单机按十万QPS来算,我们至少需要十台Redis实例,所以下一步还要将存储分散存储(去除热点数据),即不论是采用BloomFilter还是Bitmap实现,都应该将数据尽可能的分散在十台redis上,比如定义十个bitmap的数据结构,按uid对十取模分别存储在这十个bitmap里(BF亦然),这样我们读写均支持定位相应的bitmap。
视具体redis操作或为了预留足够算力,可能redis不止十台,比如选择十六台,那么取模操作也可做位运算提高一点性能。
实现
上文中笔者选择Redis作为数据存储,算法/数据结构 则需要在bitmap和BF之间做个选择, 但不论何,二者均支持构造多个对象(比如16个),按UID对16取模并分散存储到这16个对象里,这里不再详述,下面主要讨论下bitmap或BF的选择。
Bitmap
bitmap思想应用很广,《编程珠玑》里就有介绍:
“Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。”
用于大量数据的排序/查询/去重,还是蛮简单的,比如常见的10亿int型数据排序/去重都可用bitmp思想。
位图也是Linux内核在大量使用的基础数据结构,此外也常见于标签系统以及大数据系统做一些快速的集合操作。
在Java中使用BitSet实现位图,重要方法有set/get(bit):
1 | private long[] words; |
Java bitset底层使用long型数组(long[] words)实现,所以set时需要计算wordIndex,wordIndex即是 bitIndex除以64即右移6位得到,同时我们也可以看到有个expandTo方法,即bitSet是可以自动扩展位数的(但最好一开始就规划好,否则频繁expandTo影响性能),wordIndex得到对应long,再和 1L << bitIndex 异或从而设置对应bit位,注意这里1L本身即是long,所以可以直接 右移 bitIndex不需要在对64取模后异或了。
get就比较简单了,直接对该位做 且1判0操作。bitset怎么去将该位set为0呢?就是clear()方法,通过 words[wordIndex] &= ~(1L << bitIndex); 即反码做且运算。此外其底层存储使用 long[] words思想还是蛮有技巧性的。
此外bitset计算位1的个数方法为 cardinality(), 遍历words并用Long.bitCount()累加 各words的位1数量。
这里的Long.bitCount()提供了一种高效的计算long型数据里1的数量的方法,值得一看, 即是大名鼎鼎的MIT Hakmem Counting算法。
同时也可以看到 java bitSet的set操作不是线程安全的(set/expandTo),需要调用者保证。
同样的Redis在2.2版本加入了 setbit,getbit,bitcount 命令也支持bitmap。
BloomFilter
上述不论redis或java,实现bitmap都需要不小的空间,int型就已经512MB了,所以是否存在其他时间换空间方法呢?
Bloomfilter就提供了思路,笔者前面文章有介绍BF原理,这里不详述。
BF另外一个好处是不用再考虑其是32位或64位,只需要考虑数量,即使用BF无需考虑uid的可能范围,只要根据可能插入的uid的数量和误差率计算所需bit数量,即对于1亿的用户量百万分之一的误判率所耗费的空间也不过343MB。
当然Redis目前是不支持BF的,但是依赖redis的bitmap可以实现。
通常有:
1,Redis BF插件 Rebloom
Rebloom,现位于RedisBloom 是redis labs 实现的BF插件,从github下载源码编译后得到rebloom.so,
然后在redis.conf里面添加 loadmodule /path/to/rebloom.so 或者直接命令行动态加载该module,即可将其加载到redis中。
推荐该做法,因为这是redislab官方C代码实现,理论上会比下面介绍的lua或调用bitmap更快,官方声称的“Highly optimized for performance”,这里有和lua实现的对比Integrated Modules,因为相对bitmap来说,BF就是一种时间换空间的做法,所以性能会差点,下面介绍的2、3方案视BF各参数性能在2-6万/s间,小于Rebloom性能的。
其次该插件数据丰富,目前提供了Bloom filter, Cuckoo filter, Count-min sketch, top-k等,这几类都较实用。当然需要redis 4.0以上支持。
对于Java/Go/Python等 redisbloom均有对应client实现,或者自己基于jedis扩展也可。
另外ReBloom是源码可用的,但和redis不同的是,其不再属于开源协议,几年前增加了Commons Clause(共用条款)约定,不支持二次销售,这可能对许多拿来主义的云供应商不友好。
2,Redis client组件如Jedis/Redisson等
这类组件也是基于redis的bitset实现,代码里初始化bit空间,然后计算出BF的每轮hash得到的index,根据index设置,这里有段redisson里的代码:
RedissonBloomFilter.java
1 |
|
其中第一次hash:long[] hashes = hash(object)是哈希得到128位(两个long)结果,第二个hash,即是其BF的哈希函数,用来一次性计算需设置1的位,hashIterations是所需哈希函数次数,size即是所需位空间。
关于Jedis/Jedisson以及其他语言的BF实现,可在网上找到大多代码,这里不再详述。
不过还要指出的是,我们实现BF显然是针对同一redis instance,而了解BF原理的,大多知道BF时hash计算出需要设置的位一般不会只一个(几十到一百可能),这里完全可以使用pipeline提升性能(这里不讨论pipeline带来的其他影响),所以参考网上的BF的jedis实现时留意下这里的改进,上述Redisson实现用到了RBatch批量更新就是基于pipeline的,性能会好些。
但Redisson实现的BF不是没有问题,比如批量设置bit时未使用事务不能保证100%准确。
另:(jedis实现:restes-Bloomfilter)[https://github.com/Baqend/Orestes-Bloomfilter]
3,Redis Lua实现的BF
基于lua脚本实现的BF,原理和上述1、2相似,这里有一个参考实现redis-lua-scaling-bloom-filter:
1 | ... |
setbit返回值是原始值,所以上述BF.add的返回值也可表示是否命中,found的逻辑是只要一个为0即false,这点和上述redisson是一样的。
另外这个脚本里,作者测试的add和check性能都在 2.5万/s左右。
bitmap存在的问题
上述BF的实现依赖redis的setbit命令,redis目前没有类似 msetbit这样设置多个bit位指令,所以上述实现都是多次setbit的,
不过3.2后支持bitfield指令,可以批量设置bit位(至于在Bloomfilter场景下和pipeline+setbit性能比较笔者未测)。
其次BF最大的问题就是精确度问题,需要按 $ m=-n*l(p)/(l(2)^2) $ 评估假阳率。
除此以外,bitmap是比较耗空间的,比如这个简单的设置一个2^32长的bitmap就能让redis占用内存瞬间涨了512MB,虽然只保存两条信息:
1 | setbit mybmp 0 1 |
在官方文档里 setbit 的offset是有大小限制的,在0到 2^32(最大使用512M内存)之间,即0~4294967296之前,超过这个数会自动将offset转化为0,因此使用的时候一定要注意。
其次setbit自身不是没有性能问题的,经测试, 初次分配或者扩展相应的bit空间也是耗时的,在2010 MacBook Pro上,
1 | setting bit number 2^32 -1 (512MB allocation) takes ~300ms, |
可以看到setbit:
- 耗费空间大,存在32位限制的,不支持64位
- 应该避免频繁setbit带来的空间分配
这里也提醒我们使用redis原生bitmap是一定要规划好位数,保证足够长,否则频繁扩展空间带来会性能尖刺。
Roaring Bitmap
上述举了个只存储一条信息耗费512MB极端情况的例子,所以想当然做法就是压缩bitmap,bitmap本身可认为是一种信息的压缩,怎么进一步压缩?
我们知道,通常意义上的压缩分为有损压缩和无损压缩,BloomFilter就可以认为是有损压缩,无损压缩我们常见有Lz77、Zigzag等,甚至简单如类似Lucene等常见变长的vint也算,而像上述512MB极端情况,其实我们可参考这种想法,原始数据不需bitmap,像笔者之前文章里介绍的redis几个个数超过300可改用Hyperloglog,当超过一定数量再改用bitmap就是一种“压缩”方案,我们也可以采用对64bit分段方式压缩存储。
Roaring Bitmap即是接近上述的一种压缩方案,这里是官网:Roaring Bitmaps,可以看到他的历史并不久,较知名的论文是2016年的 Better bitmap performance with Roaring bitmaps,可以看到 Google、Lucene、Hive、InfluxDB、ClickHouse、Kylin都有使用,也可以看到2016年时候还是蛮活跃/流行的,如SPARK-18252以及下文几处开源代码的链接,这里是官方列出的对各语言支持情况 http://roaringbitmap.org/software/。
这里简介下32位的RoaringBitmap,部分文字引用自高效压缩位图RoaringBitmap的原理与应用:
RoaringBitmap将int数字的高16位作为索引,正好short是16位长度,因此索引采用short数组存储,而低16位则是作为数据,存储到其他容器,RoaringBitmap根据存储的大小,分为3个容器,ArrayContainer,BitmapContainer,RunContainer。BitmapContainer查找是O(1),其他为O(lgn)。RoaringArray用于通过高位定位Container,RoaringBitmap本身是一系列上述三类Container集合。
ArrayContainer
当桶内数据的基数不大于4096时,会采用它来存储,其本质上是一个unsigned short类型的有序数组。数组初始长度为4,随着数据的增多会自动扩容(但最大长度就是4096)。另外还维护有一个计数器,用来实时记录基数,当ArrayContainer的容量超过4096后,会自动转成BitmapContainer存储。
BitmapContainer
当桶内数据的基数大于4096时,会采用它来存储,其本质就是上一节讲过的普通位图,用长度固定为1024的unsigned long型数组表示,亦即位图的大小固定为216位(8KB)。它同样有一个计数器。
RunContainer
RunContainer是后续加入折中方案,它使用可变长度的unsigned short数组存储,基于Run Length Encoding压缩算法的容器,其压缩原理是对于连续的数字只记录初始数字以及连续的长度,比如有一串数字 2,3,4,5,6 那么经过压缩后便只剩下2,5。从压缩原理我们也可以看出,这种算法对于数据的紧凑程度非常敏感,连续程度越高压缩率也越高。通过optimize从BitmapContainer转化RunContainer之前需要判断是否占用内存更小。
这里贴一张图,便于理解RoaringBitmap,图来自TT: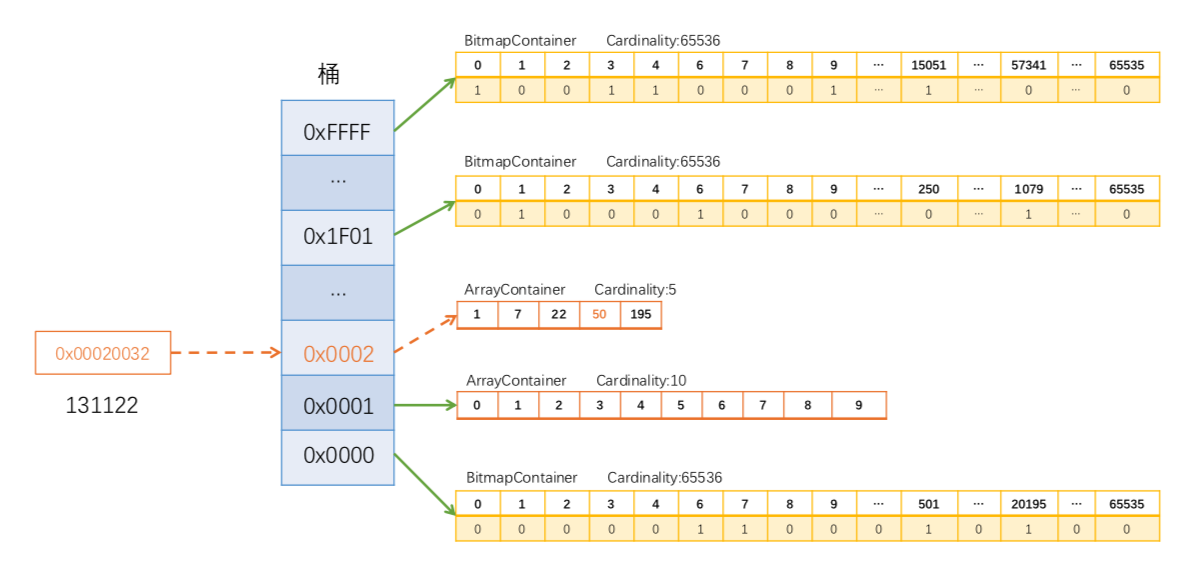
需要指出的是,RoaringBitmap未必一定是起到压缩作用的,这是因为基于行程长度编码(RLE)的压缩比率依赖压缩内容,这也是为什么说RunContainer相对itmapContainer是一种折中。
Redis roaring bitmap有个开源实现 redis-roaring,性能比原生bitmap有优有劣,主要的get/setbit操作是几乎相等的(不过这个测试数据很可能不准确,或者作者只测试静态的数据,没有考虑增加数据过程中的压缩消耗)。不过可惜的是redis-roaring也只支持32位,显然我们不能通过将long拆成两个int并各自存储在roaring bitmap实现64位的bitmap。
如redis-roaring是基于CRoaring的,理论上可以修改支持,不过 原讨论里提到CRoaring 64bit的性能似乎不够好。
这里 Daniel Lemire 提到了几个Java支持64bit的实现 Implement support for 64-bit integers,分为两层或48-16bit实现,这里不再详述。
遗憾的是笔者没有搜索到基于redis lua的roaring bitmap(含64-bit支持)实现,所以这个方案未进行下去。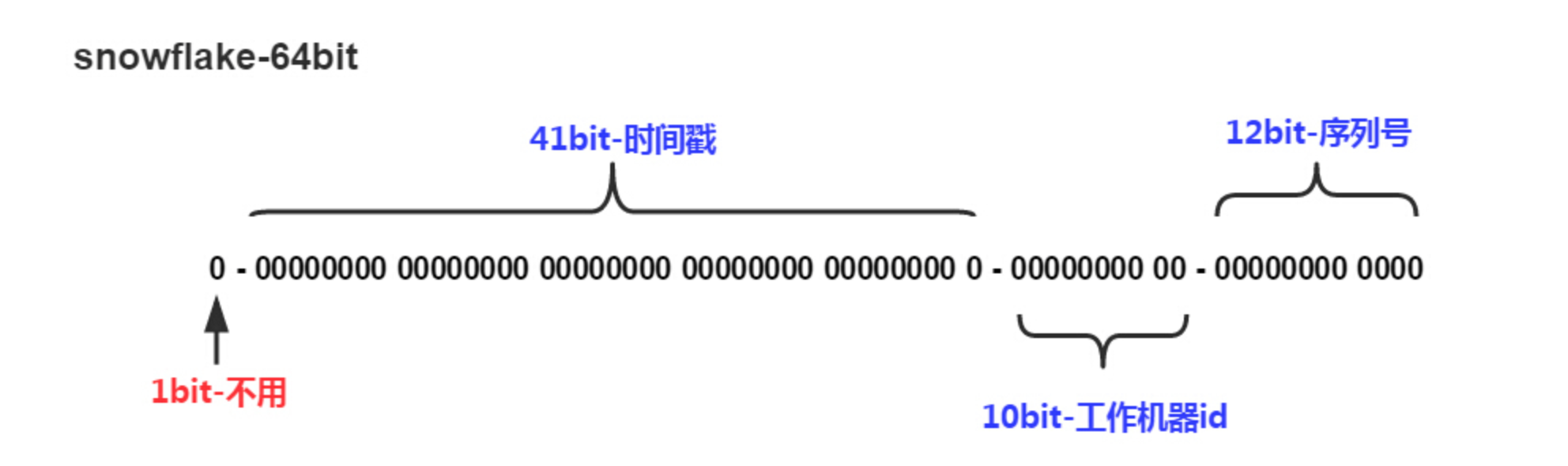
不过上述压缩给了一种思路,但仅考虑snowflake算法,不具有64bit通用性:
我们知道全球用户数量一半假设40亿,32bit足够了,不过通常来说,比如压缩64bit到32bit会丢失信息,但考虑到uid生成算法本身具有规律性,而且我们前文讨论过将bitmap按uid取模分成16份(减少热点,保证redis分布式性能),也就是说uid末四位bit可以不参与Roaring bitmap运算,其次似乎也能保证均衡分布,但实际上图示snowflake算法末12bit是自增序列,表示该毫秒增长数,对于用户id分配场景,我相信世界上大部分应用这12bit大部分时间是0,其次可能就是小于16或个位数了,所以按uid哈希很容易造成分布不均匀,对压缩贡献度也很低。所以这表示自增的12bit和workerid的10bit完全是可以合起来压缩的,表示时间戳的41bit(毫秒,约69年)其中末4位bit我们可以用来做模16的分库,保证均衡,如果我们只统计8年的用户,那么又可减少3个bit了(当然精确性降低了),即时间戳部分实际上34bit有效,所以我们也可以参考64bit roaring bitmap分层的思路。
需要指出的是,时间戳如果不考虑好高位,可能会导致分布也不均匀,因为对于国内来说统一使用东八区,而我们的用户注册时间通常不会是夜间,如23-08这几个小时的数据量会较其他时间稀疏,通过redis lua实现时需要考虑这点是否有助压缩。
高可用/一致性
需要指出的是,不管redis如何高可用,主从异步的同步存在时间差的,比如min-slaves-max-lag等参数,当主节点挂掉时从节点数据可能是存在误差的,尤其是对于百万QPS来说,当然这是分布式系统的CAP问题了,任何非强一致性的存储必然存在的问题了,这里只是指出一下,设计或实现该系统时最好也留意下底层存储的一些参数,否则自信的脱口而出4个9/5个9的保证不是明智的做法。
其次,上面只是解决底层存储满足支持百万QPS的64位的uid唯一性检验的问题,在实际实现中还要考虑其他问题,如如何保证bitmap或者BF更新和你的业务一致性问题,即应用更新了bitmap操作之后业务更新操作失败或者反过来,这其实的确是一个分布式事务的问题,对于要求不强场景或许先更新业务成功再更新bitmap操作就能满足需求,或者对于响应要求不强场景有人使用分布式事务解决(BF实现不支持TCC,如果基于BF实现你可能需要改进的CBF),但这其实也只是解决部分问题,以抢红包为例,除了更新bitmap后服务端可捕捉的异常(自身或其他以来系统),还有返回给用户超时的情况,这加大了分布式事务的复杂性,有节制的使用分布式事务是一点,端到端的追踪/审计/对账也是一点,当然这些超出本文要讨论的内容了,如果你有好的方案也欢迎赐教。
其他
1,Roaring bitmap可能会导致bit数组做 or/and等操作较bitmap耗时,尤其RunContainer压缩的情况。
2,上述提供集中redis分布式BF的实现,值得参考。
很多人知道回答“怎么实现防止缓存击穿”之类问题时可以用 bloom filter,但可能很多只认为这个BF实现是在应用程序内存自己维护BF,其实不是,可以参考这里实现一个基于redis的集中式 bloom filter对象。
当然,像Redis已经支持客户端缓存(client side cache),6.0开始使用的RESP3协议可以即时push方式更新,开启后可保证client和远程redis server之间数据一定程度的一致性,这个特性也可以提高上述场景下的性能。
参考
- RedisBloom
- redis-lua-scaling-bloom-filter
- Roaring Bitmaps
- Better bitmap performance with Roaring bitmaps
- redis setbit
- 高效压缩位图RoaringBitmap的原理与应用
- RoaringBitmap Performance Tricks
** 遵循CC协议,转载请标注来源 **