分享一下在学习逻辑回归时候的困惑,以便需要者节约时间。
在看西瓜书的逻辑回归这一章时,对作者引入了sigmoid函数觉得突兀,于是搜索到了知乎上的提问,为什么 LR 模型要使用 sigmoid 函数 里获赞最高的答案。
但正如马化腾先生说的,这么说,也对也不对。
看完后,上面其他回答各种理由,而匿名回答是最大熵的,并不是原因,甚至,这可以认为是一个推论或公理。试想再问为什么要熵最大化?
换言之,一个分析问题是从前一步的因,一个分析问题是从最初的因。这对数学专业可能会直接跳过这么问。
那么让我们将问题拆开来看:
1, 逻辑回归为什么要使用sigmoid函数.
2, LR模型的意义,即为什么有了线性回归(linear regression)还需要逻辑回归(logistic regression)
问题一
很好解释:其实没有什么原因。
看上面高赞答案解释一堆,或者下面解释sigmoid函数好用,好求导。其实都不是原因。
因为逻辑回归对应Logit Function,即逻辑回归就是sigmoid函数的应用,
一个对象的两个描述而已,像原文这么问就像是在问为什么抛物线方程要使用 y= a*x^2+bx+c表示一样。
逻辑回归,不过是结果sigmoid函数化的线性回归而已。
但,为什么要有这个定义?为什么要将线性回归的值sigmoid化?这就是下面要说的。
问题二
上面解释了为什么LR对应sigmoid函数,但可能会继续好奇为什么有Logistic Regression?常规的linear regression不满足吗?这是一个数学问题, 在许多现代跟统计/概率学相关学术问题里被广泛使用,其实回归分析很多方法,比如linear/logistic/Polynomial等,分别适用于不同模型。
我们先看线性回归:
$$Y = X\beta + \epsilon $$
$$J(\theta) = \sum_{i=1}^m (h\theta(x^{(i)})-y^{(i)})^2$$
Linear Regreesion的损失函数就是常见的均值方差也就是平方损失函数,最优求解即是使用高斯的最小二乘法,高中数学都会讲到,这里不详述。
那么,线性回归有什么问题嘛?线性回归适用于因变量(随自变量而变)是连续的模型,即特征和结果满足线性,但是实际有的因变量是离散型机率分布。如抛硬币,结果是正面或反面的二项分布问题。
LR用来处理预测结果为0-1的二值分类问题(二态问题其实是一个普遍存在自然界的问题)。这里假设了二值满足了伯努利分布。
Logistic Distribution
随机变量X服从逻辑斯蒂分布,即X的累积分布函数为上文提到过的logistic function。对分布函数求导得到了概率密度函数。公式如下:
$$F(x) = P(X \leqslant x) = \frac{1}{1+e^{-(x-\mu)/\gamma}}$$
$$f(x) = F’(x) = \frac{e^{-(x-\mu)/\gamma}} { \gamma (1+e^{-(x-\mu)/\gamma})^2 }$$
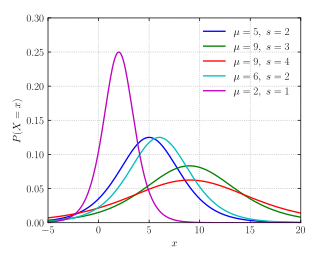
Logistic分布的密度函数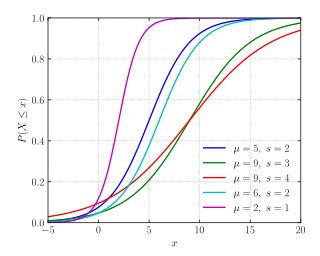
Logistic分布的分布函数
进一步
$$P(Y=1|x)=\frac{e^{w\cdot x+b}}{1+e^{w\cdot x+b}} \:\:\:\:\:\:\:\:\:(1)$$
$$P(Y=0|x)=\frac{1}{1+e^{w\cdot x+b}} \:\:\:\:\:\:\:\:\:(2)$$
又对一个二分类事件发生的几率odds的对数有
$$logit(P(Y=1|x)) = log\frac {P(Y=1|x)}{1-P(Y=1|x)} = w\cdot x$$
这里我们可以定义LR模型:输出Y=1的对数几率是由输入x的线性函数表示的模型。
线性回归是连续型模型,用于分类的问题时受噪声影响比较大,logistic回归是非线性模型(上文),本质上是线性回归模型,但logistic回归巧妙之处在于其将结果值经一层函数映射在0-1上,即在特征到结果的映射中加入了一层函数映射(对数损失函数),也就是本文的sigmoid function。
在《统计学习方法》第六章里已经在做推导。引入最大似然的概念,那么二项式对应的最大熵的解等价于二项式指数形式的最大似然解,为我们前面提到的二项式分布到的熵分布最大,这就必然会引入二项式指数形式的最大似然解,也就是这里采用logit函数原因,也就是本文试图解释的要用sigmoid的原因。
具体推导,在《统计学习方法》P80-P88,或点击,下标1-7。
也可以参考: 逻辑回归和最大熵模型
,The equivalence of logistic regression and maximum entropy models
{kind=link}
参考:
- wikipedia:
Logistic_function,
Logistic_distribution,
Logistic_regression - 知乎为什么 LR 模型要使用 sigmoid 函数
- 《统计学习方法》.李航著