We assume that there are many partitions in a cluster and try to spread the leaders evenly among brokers. That way, even for a particularpartition, all clients have to talk to a single broker, the overall workload is still balanced.
Brokers Spread:看作broker使用率,该topic分布的broker占集群broker总量百分比 Brokers Skew:该topic偏离均值的broker占集群broker总量百分比 Brokers Leader Skew:Percentage of brokers having more partitions as leader than the average, leader partition是否存在倾斜,即没有达到平均leader比重的broker数量占集群broker总量百分比
ControllerContext.scala ... privatedefcheckAndTriggerPartitionRebalance(): Unit = { if (isActive()) { trace("checking need to trigger partition rebalance") // get all the active brokers var preferredReplicasForTopicsByBrokers: Map[Int, Map[TopicAndPartition, Seq[Int]]] = null inLock(controllerContext.controllerLock) { preferredReplicasForTopicsByBrokers = controllerContext.partitionReplicaAssignment.filterNot(p => deleteTopicManager.isTopicQueuedUpForDeletion(p._1.topic)).groupBy { case(topicAndPartition, assignedReplicas) => assignedReplicas.head } } debug("preferred replicas by broker " + preferredReplicasForTopicsByBrokers) // for each broker, check if a preferred replica election needs to be triggered preferredReplicasForTopicsByBrokers.foreach { case(leaderBroker, topicAndPartitionsForBroker) => { var imbalanceRatio: Double = 0 var topicsNotInPreferredReplica: Map[TopicAndPartition, Seq[Int]] = null inLock(controllerContext.controllerLock) { topicsNotInPreferredReplica = topicAndPartitionsForBroker.filter { case(topicPartition, replicas) => { controllerContext.partitionLeadershipInfo.contains(topicPartition) && controllerContext.partitionLeadershipInfo(topicPartition).leaderAndIsr.leader != leaderBroker } } debug("topics not in preferred replica " + topicsNotInPreferredReplica) val totalTopicPartitionsForBroker = topicAndPartitionsForBroker.size val totalTopicPartitionsNotLedByBroker = topicsNotInPreferredReplica.size imbalanceRatio = totalTopicPartitionsNotLedByBroker.toDouble / totalTopicPartitionsForBroker trace("leader imbalance ratio for broker %d is %f".format(leaderBroker, imbalanceRatio)) } // check ratio and if greater than desired ratio, trigger a rebalance for the topic partitions // that need to be on this broker if (imbalanceRatio > (config.leaderImbalancePerBrokerPercentage.toDouble / 100)) { topicsNotInPreferredReplica.foreach { case(topicPartition, replicas) => { inLock(controllerContext.controllerLock) { // do this check only if the broker is live and there are no partitions being reassigned currently // and preferred replica election is not in progress if (controllerContext.liveBrokerIds.contains(leaderBroker) && controllerContext.partitionsBeingReassigned.size == 0 && controllerContext.partitionsUndergoingPreferredReplicaElection.size == 0 && !deleteTopicManager.isTopicQueuedUpForDeletion(topicPartition.topic) && controllerContext.allTopics.contains(topicPartition.topic)) { onPreferredReplicaElection(Set(topicPartition), true) } } } } } } } } } /** * This callback is invoked by the reassigned partitions listener. When an admin command initiates a partition * reassignment, it creates the /admin/reassign_partitions path that triggers the zookeeper listener. * Reassigning replicas for a partition goes through a few steps listed in the code. * RAR = Reassigned replicas * OAR = Original list of replicas for partition * AR = current assigned replicas * * 1. Update AR in ZK with OAR + RAR. * 2. Send LeaderAndIsr request to every replica in OAR + RAR (with AR as OAR + RAR). We do this by forcing an update * of the leader epoch in zookeeper. * 3. Start new replicas RAR - OAR by moving replicas in RAR - OAR to NewReplica state. * 4. Wait until all replicas in RAR are in sync with the leader. * 5 Move all replicas in RAR to OnlineReplica state. * 6. Set AR to RAR in memory. * 7. If the leader is not in RAR, elect a new leader from RAR. If new leader needs to be elected from RAR, a LeaderAndIsr * will be sent. If not, then leader epoch will be incremented in zookeeper and a LeaderAndIsr request will be sent. * In any case, the LeaderAndIsr request will have AR = RAR. This will prevent the leader from adding any replica in * RAR - OAR back in the isr. * 8. Move all replicas in OAR - RAR to OfflineReplica state. As part of OfflineReplica state change, we shrink the * isr to remove OAR - RAR in zookeeper and sent a LeaderAndIsr ONLY to the Leader to notify it of the shrunk isr. * After that, we send a StopReplica (delete = false) to the replicas in OAR - RAR. * 9. Move all replicas in OAR - RAR to NonExistentReplica state. This will send a StopReplica (delete = false) to * the replicas in OAR - RAR to physically delete the replicas on disk. * 10. Update AR in ZK with RAR. * 11. Update the /admin/reassign_partitions path in ZK to remove this partition. * 12. After electing leader, the replicas and isr information changes. So resend the update metadata request to every broker. * * For example, if OAR = {1, 2, 3} and RAR = {4,5,6}, the values in the assigned replica (AR) and leader/isr path in ZK * may go through the following transition. * AR leader/isr * {1,2,3} 1/{1,2,3} (initial state) * {1,2,3,4,5,6} 1/{1,2,3} (step 2) * {1,2,3,4,5,6} 1/{1,2,3,4,5,6} (step 4) * {1,2,3,4,5,6} 4/{1,2,3,4,5,6} (step 7) * {1,2,3,4,5,6} 4/{4,5,6} (step 8) * {4,5,6} 4/{4,5,6} (step 10) * * Note that we have to update AR in ZK with RAR last since it's the only place where we store OAR persistently. * This way, if the controller crashes before that step, we can still recover. */ defonPartitionReassignment(topicAndPartition: TopicAndPartition, reassignedPartitionContext: ReassignedPartitionsContext) { val reassignedReplicas = reassignedPartitionContext.newReplicas areReplicasInIsr(topicAndPartition.topic, topicAndPartition.partition, reassignedReplicas) match { casefalse => info("New replicas %s for partition %s being ".format(reassignedReplicas.mkString(","), topicAndPartition) + "reassigned not yet caught up with the leader") val newReplicasNotInOldReplicaList = reassignedReplicas.toSet -- controllerContext.partitionReplicaAssignment(topicAndPartition).toSet val newAndOldReplicas = (reassignedPartitionContext.newReplicas ++ controllerContext.partitionReplicaAssignment(topicAndPartition)).toSet //1. Update AR in ZK with OAR + RAR. updateAssignedReplicasForPartition(topicAndPartition, newAndOldReplicas.toSeq) //2. Send LeaderAndIsr request to every replica in OAR + RAR (with AR as OAR + RAR). updateLeaderEpochAndSendRequest(topicAndPartition, controllerContext.partitionReplicaAssignment(topicAndPartition), newAndOldReplicas.toSeq) //3. replicas in RAR - OAR -> NewReplica startNewReplicasForReassignedPartition(topicAndPartition, reassignedPartitionContext, newReplicasNotInOldReplicaList) info("Waiting for new replicas %s for partition %s being ".format(reassignedReplicas.mkString(","), topicAndPartition) + "reassigned to catch up with the leader") casetrue => //4. Wait until all replicas in RAR are in sync with the leader. val oldReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition).toSet -- reassignedReplicas.toSet //5. replicas in RAR -> OnlineReplica reassignedReplicas.foreach { replica => replicaStateMachine.handleStateChanges(Set(newPartitionAndReplica(topicAndPartition.topic, topicAndPartition.partition, replica)), OnlineReplica) } //6. Set AR to RAR in memory. //7. Send LeaderAndIsr request with a potential new leader (if current leader not in RAR) and // a new AR (using RAR) and same isr to every broker in RAR moveReassignedPartitionLeaderIfRequired(topicAndPartition, reassignedPartitionContext) //8. replicas in OAR - RAR -> Offline (force those replicas out of isr) //9. replicas in OAR - RAR -> NonExistentReplica (force those replicas to be deleted) stopOldReplicasOfReassignedPartition(topicAndPartition, reassignedPartitionContext, oldReplicas) //10. Update AR in ZK with RAR. updateAssignedReplicasForPartition(topicAndPartition, reassignedReplicas) //11. Update the /admin/reassign_partitions path in ZK to remove this partition. removePartitionFromReassignedPartitions(topicAndPartition) info("Removed partition %s from the list of reassigned partitions in zookeeper".format(topicAndPartition)) controllerContext.partitionsBeingReassigned.remove(topicAndPartition) //12. After electing leader, the replicas and isr information changes, so resend the update metadata request to every broker sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicAndPartition)) // signal delete topic thread if reassignment for some partitions belonging to topics being deleted just completed deleteTopicManager.resumeDeletionForTopics(Set(topicAndPartition.topic)) } }
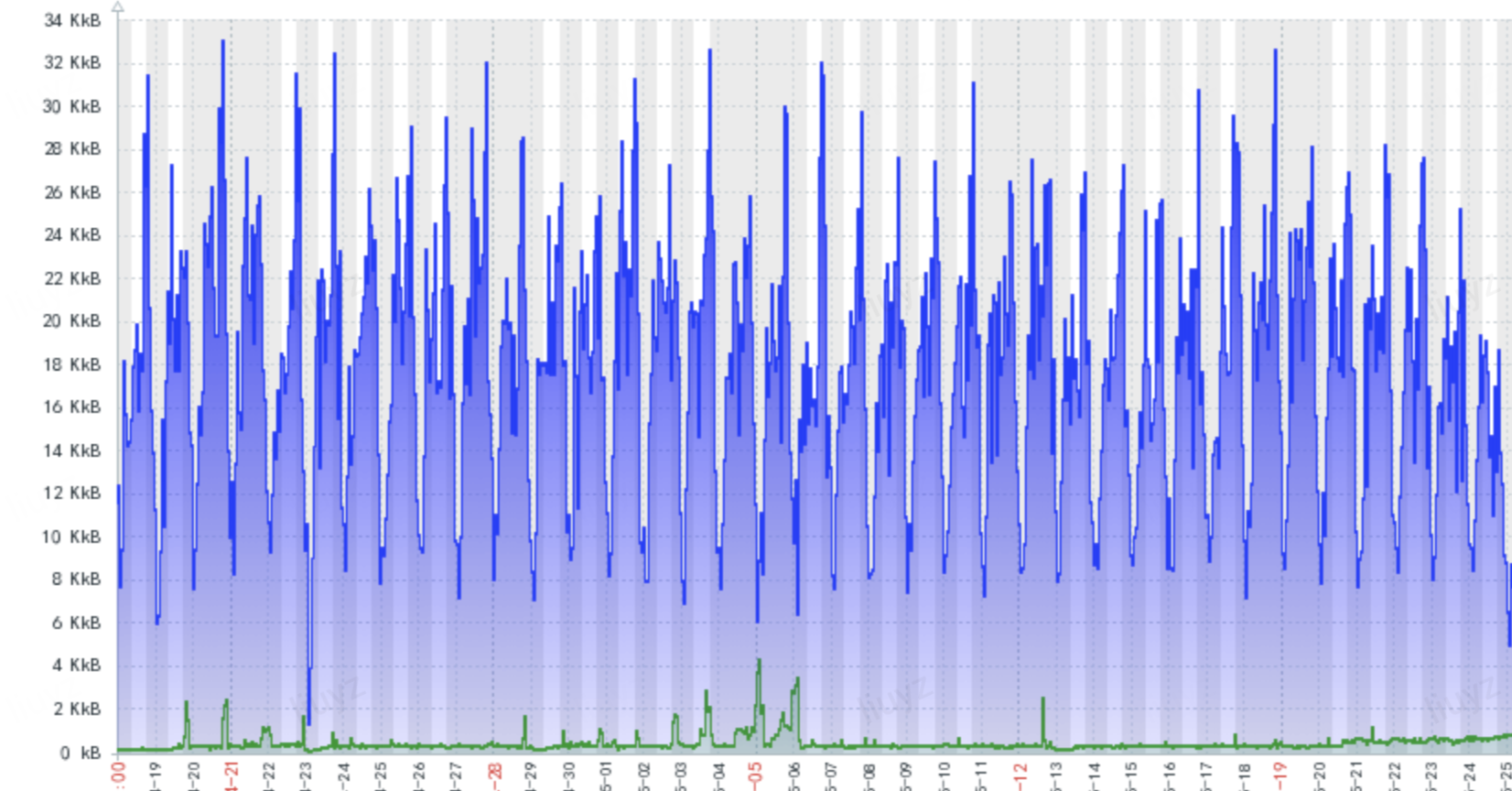 放大看,io持续还是明显的
放大看,io持续还是明显的
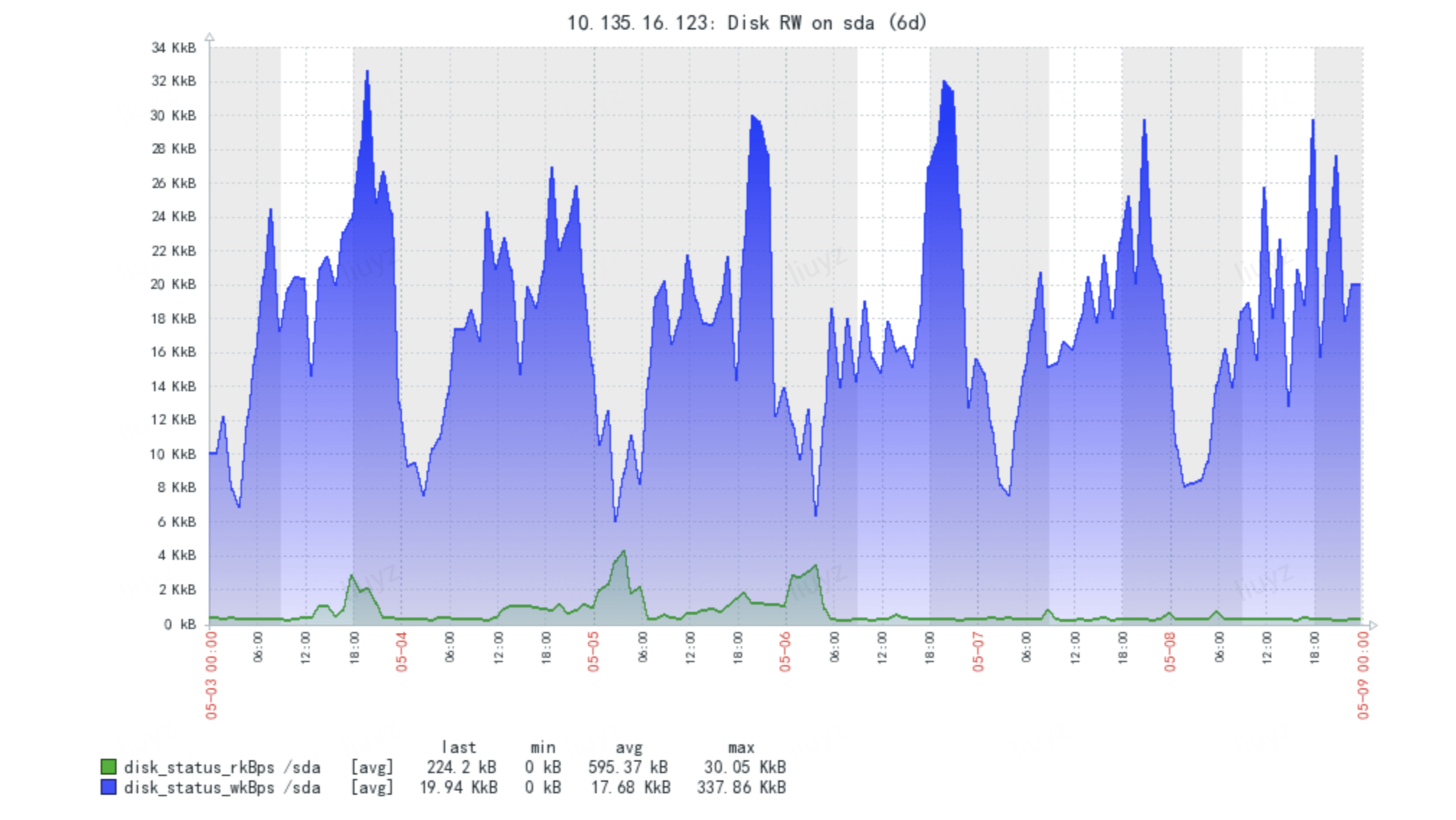 从上述图能够看出,Kafka非常少有大量读磁盘的操作,主要还是定期批量写磁盘操作,而且顺序写操作磁盘非常高效。但为什么上图最近读磁盘增加了许多呢?我们知道Kafka在写消息时,消息实际上时写入page cache(内存)中,然后由异步线程刷盘,消息从page cache落地磁盘。而读取消息时,是直接由page cache转入socket发送出去[也即大家说的零拷贝技术]。如果page cache没有命中相应数据(offset),Kafka就会通过idx文件,即索引,定位到对应的数据文件,将整个文件从磁盘加载消息到page cache,然后再从socket发出去,此时就会发生不小的磁盘读操作。
也就是说,**page cache常没有命中消费的数据,这通常是消费延迟导致**,查看消费监控,确实存在一些groupid的消费者存在严重的消费延迟情况,甚至还有程序经常从头开始消费。
这些都应该是尽量避免的,因为 **使用page cahce当遇到问题脏页,内存回收等问题时,易造成消息读写的延迟,而且过多page cache也影响linux系统本身性能,如果未关闭swap问题可能更严重了**。 不过据说来自阿里的 RocketMQ 在这方面做了些优化。
## Kafka rebalance vs Kafka reassigne
还有一点的是,我们知道Kafka读写的都是partition,partition分为leader/follower角色,在过去对于Kafka的partition来说,只有leader才会进行读写操作,folower仅进行同步/复制/备份(当然,有些例外如测试等, 不过现在更例外了,请看下文),follower对于consumer/producer等client来说是透明的,这也可以认为是kafka数据一致性的方法。
同Mysql的实现不同,Mysql分为主从,通常会针对主从作读写分离操作,实现性能提升,而Kafka则分为多个partition,读写分离到多partition上,他们的负载均衡就是通过 broker(机器)+partition+角色(leader) 的均衡实现的。
从上述图能够看出,Kafka非常少有大量读磁盘的操作,主要还是定期批量写磁盘操作,而且顺序写操作磁盘非常高效。但为什么上图最近读磁盘增加了许多呢?我们知道Kafka在写消息时,消息实际上时写入page cache(内存)中,然后由异步线程刷盘,消息从page cache落地磁盘。而读取消息时,是直接由page cache转入socket发送出去[也即大家说的零拷贝技术]。如果page cache没有命中相应数据(offset),Kafka就会通过idx文件,即索引,定位到对应的数据文件,将整个文件从磁盘加载消息到page cache,然后再从socket发出去,此时就会发生不小的磁盘读操作。
也就是说,**page cache常没有命中消费的数据,这通常是消费延迟导致**,查看消费监控,确实存在一些groupid的消费者存在严重的消费延迟情况,甚至还有程序经常从头开始消费。
这些都应该是尽量避免的,因为 **使用page cahce当遇到问题脏页,内存回收等问题时,易造成消息读写的延迟,而且过多page cache也影响linux系统本身性能,如果未关闭swap问题可能更严重了**。 不过据说来自阿里的 RocketMQ 在这方面做了些优化。
## Kafka rebalance vs Kafka reassigne
还有一点的是,我们知道Kafka读写的都是partition,partition分为leader/follower角色,在过去对于Kafka的partition来说,只有leader才会进行读写操作,folower仅进行同步/复制/备份(当然,有些例外如测试等, 不过现在更例外了,请看下文),follower对于consumer/producer等client来说是透明的,这也可以认为是kafka数据一致性的方法。
同Mysql的实现不同,Mysql分为主从,通常会针对主从作读写分离操作,实现性能提升,而Kafka则分为多个partition,读写分离到多partition上,他们的负载均衡就是通过 broker(机器)+partition+角色(leader) 的均衡实现的。
