intro1:一个不太正常的elasticsaerch分片分布场景下的扩容
intro2: elasticsaerch到底往Lucene中写了些什么数据
intro3: Lucene的文件的压缩
前文问题解答
前一篇文章,留了个Elasticsearch(以下简称ES) cpu load图猜问题,不难猜,这里贴一张磁盘图看的就更明显了。
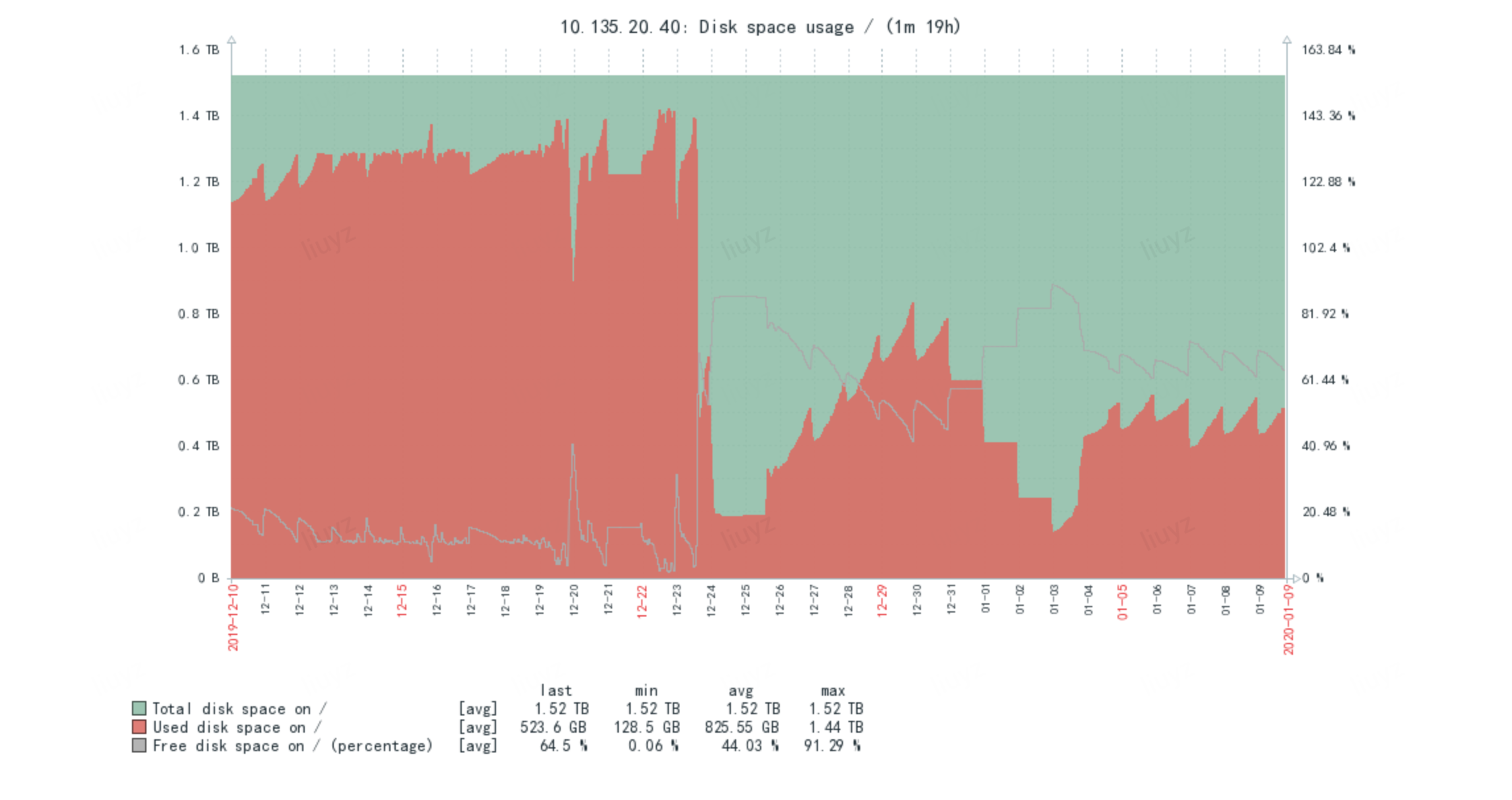 可以看到十几号已有迹象,20号明显,只不过转移或者丢弃,然后定期删除,21/22基本就无法支撑大量写入,之后是在23号下午15点挂载mfs存储,集群开始恢复,但是写入性能比之前写磁盘下降,于是25号下午15点卸载mfs,并删除更多数据来恢复,31号等来了机器之后开始扩容,主分片可以正常写入/查询,3号开启replica,至此完全恢复正常。如下图cpu/存储/网卡监控恢复。
可以看到十几号已有迹象,20号明显,只不过转移或者丢弃,然后定期删除,21/22基本就无法支撑大量写入,之后是在23号下午15点挂载mfs存储,集群开始恢复,但是写入性能比之前写磁盘下降,于是25号下午15点卸载mfs,并删除更多数据来恢复,31号等来了机器之后开始扩容,主分片可以正常写入/查询,3号开启replica,至此完全恢复正常。如下图cpu/存储/网卡监控恢复。
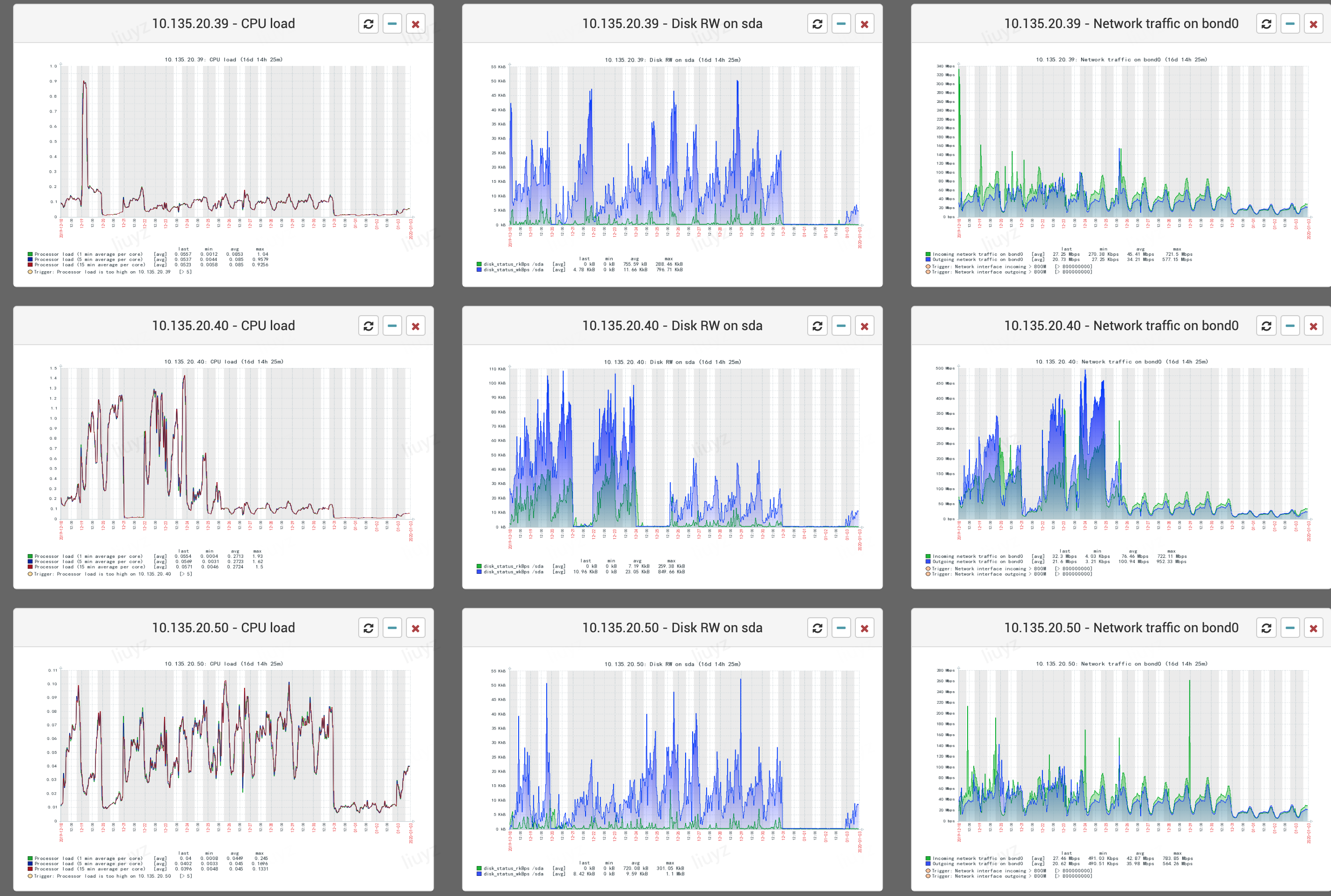 集群有8台数据节点,每台1.6-2T,索引是每天生成一份,每天大约60个新索引,并且会删除N天以前的数据,最大的索引的数据量的约20亿/日,最占存储的索引约 310GB/日(单副本),这些索引都因磁盘空间有限,调整为无副本的了。
### 那么,对于这非正常情况如何扩容,即增加数据节点呢
需要说明的是,ES官方有一个滚动升级/维修的方案,前提是需要暂停写入,**如果不停止写入索引数据时应该怎么做呢?要考虑到有些索引是没有副本的**。
如果增加节点,按官方操作,primary 分片就会被被 rebalance到新增节点上,且几百G的数据会迁移,导致往ES集群长时间写入失败,当然我们可以预先手动将已有的历史索引往新分片上迁移,足够均衡后在开启 allocation all,但需要花时间整理迁移的索引。
所以笔者想到了另外一种做法,即:
1) cluster.routing.allocation.enable设置为 new_primaries,cluster.routing.rebalance.enable 设置为none
那么启用新节点后,当前以及历史索引的 primaries 分片不受影响,故不影响现有索引读写,新索引的 primaries分配和写入也都不受影响.
2) 这样持续N天后,集群中老的索引已经被删除,剩下多是通过 new_primaries 分配的索引.
3) 此时将 cluster.routing.allocation.enable恢复为all,cluster.routing.rebalance.enable 设置为 replicas,此时至副本会被创建完成,这段时间因为异步复制数据,性能会有影响,但是可控,不过重要的是不会影响数据的写入和查询。
4) 恢复 cluster.routing.rebalance.enable 为all
需要指出的是:
1) 因为N天是单副本,还是存在数据仅一份带来的风险的。
2) 3/4步其实可以一部到位,但还是稳妥起见,其实2/3步也可以第二天开始,不必等N天。
当然上述是在允许少量数据丢失情况下懒人操作法,笔者操作下来看到还是会有接近万分之一的数据丢失。
### 如果是迁移一个数据节点呢?
**比如将故障的机器A替换为新机器B(此时机器A有当日正在写入的主分片)**,也可以通过上述 cluster.routing.allocation.enable和cluster.routing.rebalance.enable操作的方法,不过这种情况下,其实也可以通过预先创建好 第二天的索引,并将 第二日索引从A上迁移走(如果有的话),然后在第二日将A上的分片作为历史数据都迁移到B即可。
这里附上几个迁移/上下线node常用的es命令:
集群有8台数据节点,每台1.6-2T,索引是每天生成一份,每天大约60个新索引,并且会删除N天以前的数据,最大的索引的数据量的约20亿/日,最占存储的索引约 310GB/日(单副本),这些索引都因磁盘空间有限,调整为无副本的了。
### 那么,对于这非正常情况如何扩容,即增加数据节点呢
需要说明的是,ES官方有一个滚动升级/维修的方案,前提是需要暂停写入,**如果不停止写入索引数据时应该怎么做呢?要考虑到有些索引是没有副本的**。
如果增加节点,按官方操作,primary 分片就会被被 rebalance到新增节点上,且几百G的数据会迁移,导致往ES集群长时间写入失败,当然我们可以预先手动将已有的历史索引往新分片上迁移,足够均衡后在开启 allocation all,但需要花时间整理迁移的索引。
所以笔者想到了另外一种做法,即:
1) cluster.routing.allocation.enable设置为 new_primaries,cluster.routing.rebalance.enable 设置为none
那么启用新节点后,当前以及历史索引的 primaries 分片不受影响,故不影响现有索引读写,新索引的 primaries分配和写入也都不受影响.
2) 这样持续N天后,集群中老的索引已经被删除,剩下多是通过 new_primaries 分配的索引.
3) 此时将 cluster.routing.allocation.enable恢复为all,cluster.routing.rebalance.enable 设置为 replicas,此时至副本会被创建完成,这段时间因为异步复制数据,性能会有影响,但是可控,不过重要的是不会影响数据的写入和查询。
4) 恢复 cluster.routing.rebalance.enable 为all
需要指出的是:
1) 因为N天是单副本,还是存在数据仅一份带来的风险的。
2) 3/4步其实可以一部到位,但还是稳妥起见,其实2/3步也可以第二天开始,不必等N天。
当然上述是在允许少量数据丢失情况下懒人操作法,笔者操作下来看到还是会有接近万分之一的数据丢失。
### 如果是迁移一个数据节点呢?
**比如将故障的机器A替换为新机器B(此时机器A有当日正在写入的主分片)**,也可以通过上述 cluster.routing.allocation.enable和cluster.routing.rebalance.enable操作的方法,不过这种情况下,其实也可以通过预先创建好 第二天的索引,并将 第二日索引从A上迁移走(如果有的话),然后在第二日将A上的分片作为历史数据都迁移到B即可。
这里附上几个迁移/上下线node常用的es命令:
1 | curl -XPUT 10.135.20.38:9200/_cluster/settings -d'{ |
一个分词问题
笔者曾被问到如何搜索 一个超长(约530个字符串)的问题,即业务写入ES的数据有个msg字段,值是下面那段很长的文本,像这种超长的字符串,ES会怎么索引?
为什么用 7B22626F64* 可以搜索到,而 7B22626F64 却搜索不到?
该索引使用 ES 默认的 standard analyzer分词,我们看下:
1 | [java@10-135-16-105 logs]$ curl -s 10.135.20.38:9200/_analyze?text="7B22626F6479223A22222C2263726561746554696D65223A313537383338353930383736312C22657854797065223A312C22657874656E73696F6E223A227B5C227264436D645C223A7B7D2C5C2267624366675C223A7B5C22756E6B6E6F776E446973636172645C223A747275657D7D222C22666C6167223A302C2266726F6D223A223040636D642E796F756E69222C226D6964223A224F6F6566656566663434333835393037383737222C22737461747573223A302C2273756254797065223A372C2273796E634B6579223A2233222C22746F223A22343132333435363738394068656C6C6F776F726C64222C2274797065223A34322C2276657273696F6E223A31353730313430327D&pretty" |
也即这个534字节长的字符串实际上被分词分成了三个词:两个255长度的字符串,和剩下的”6e223a31353730313430327d”,所以如果不用正则/模糊查询,那我们就要用上述的 三个词(两个255长的词和6e223a31353730313430327d)作为搜索词才能查到。
ES的 StandardAnalyzer 正是下面所示类,可以看到 max_token_length 就是设置了255长度。
1 | public class StandardAnalyzerProvider extends AbstractIndexAnalyzerProvider<StandardAnalyzer> { |
题外话,笔者知道这里msg之前是json字符串,初看起来猜测试base64编码,但是没有=所以暂不考虑,仔细观察发现字符串都是以7B22开头,7D结尾,看起来是个对齐位数的编码,base32/base16解压下,发现确实base16,因为无意义,所以读者想对该字段禁用index。
Elasticsearch如何通过Lucene存储
上述 msg字段所在索引,一天可以产生310G数据,可以看下面数据, 一天单shard的tim文件已经有30GB了。
1 | -rw-rw-r-- 1 elast elast 1159905974 Dec 31 10:01 _3qr.fdt |
不过在笔者禁用 msg 的索引后,ES该Index的存储数据量降到每天110G,这个降幅让笔者有点意外。
我们知道ES底层就是通过Lucene实现索引的存储,所以先了解下,这几个后缀名文件含义:
.fdt .fdm .fdx 其中.fdt(field data)用于存储具有Store.YES属性的Field的数据,fdx/fdm则是对fdt的索引。
.tim .tip .doc 其中 .tim 存储倒排索引的文件,它存储了分词后的词条(Term)和doc的索引信息
.dvd .dvm 用于聚合排序的列存文件
.cfs 是复合索引格式,就是上述后缀文件的大杂烩,es IndexWriter的useCompoundFile默认true,就是该功能,这是性能考虑,为了减少索引文件数量,减少同时打开的文件数量。
更多可以参考 Apache Lucene - Index File Formats
Elasticsearch底层 到底 往Lucene写入了些什么
很简单,这是笔者 通过Luke查看一段 ES 的一个索引看到的数据,如图示: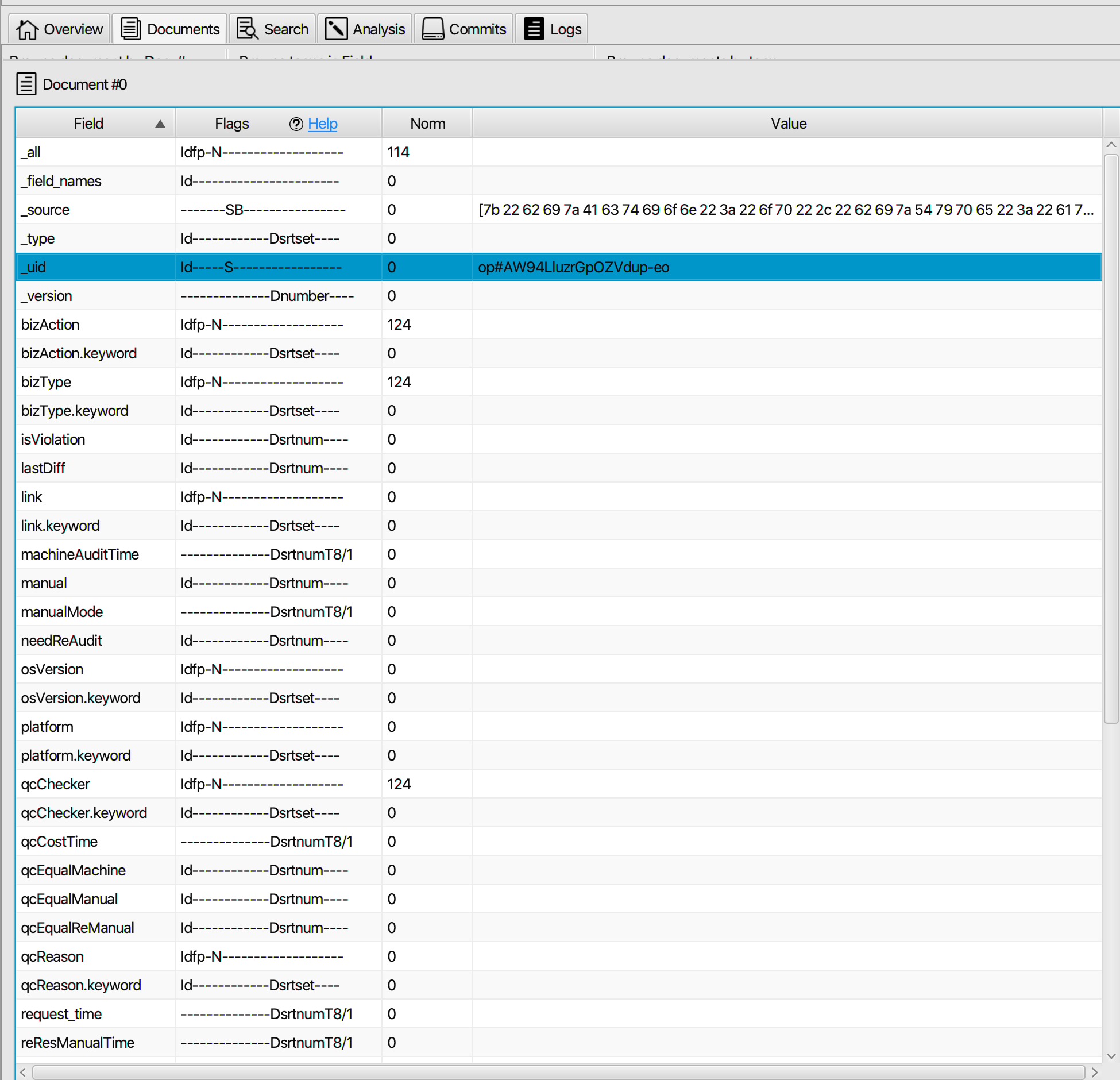
我们首先可以看到 _all,_source,_uid,_type,_version,_field_names 这些下划线开头的字段名,这些就是属于ES的元数据
_source就是大家熟知的写入es的消息体内容,_all 是把所有其它(indexed)的字段值合并成一个大字符串来索引的特殊字段,_field_names就是字段名的索引(用于es的_exists_查询),但图中的 _uid 字段是什么呢?其实就是ES的 _id 字段,只不过ES在内部使用 _uid(_uid的格式是:type + ‘#’ + id)实现,即把_uid存储在Lucene中,关于ES的内部字段,可以参考: https://blog.csdn.net/zhaipengfei1231/article/details/80031261 ,这里不展开。
同时我们还可以看到许多如 msg、name等一些业务字段,而这些字段都对应着一个 XX.keyword 字段。
从图上看到,ES写入Lucene的 字段,除了_uid和_source,其他字段都是 不存储到 Lucene中的,即这些field都是Store.NO !
这些字段的type都可以在ES的org.elasticsearch.index.mapper package下看到源码,比如_source 这个field type 可以看到它是 store,但不索引,不参与index-time boosting
1 | public static final MappedFieldType FIELD_TYPE = new SourceFieldType(); |
同时我们还可以看到 _source 的值为 “7b 22 62 69 7a 41 63 74 69 6f 6e 22…”这一串,其实是因为 源数据是作为二进制的Byte存入 _source并写入Lucene的,即将 _source值拷贝出来,通过HEX 解码,我们就可以得到源数据。
但为什么去掉msg后就可以节省66%的空间?
我们知道,ES借助Lucene有许多压缩,比如_source的存储,就会以LZ4的方式被压缩存储,也就是ES官方默认和推荐的压缩方式:Best Speed,另外一种方式是 Best Compressed。Elasticsearch Tune for disk usage
LZ4是通用的非常快的压缩/解压算法,但是压缩比不好,Deflate(通常如gzip压缩)压缩比较好,但是耗时,因为Deflate首先也是基于LZ77压缩,然后再经Huffman编码再压缩,所以理论上压缩更少,但压缩也更耗时。
好了,我们看看上文提到.tim文件,即倒排索引文件,无论其数据格式如何,底层实际是保存了倒排索引需要的 term 和doc(doc id) 的索引关系,那么这个term的内容是否需要压缩呢?
通常经过分词后得到的就是极小的词单元,已经是小文本了,再压缩似乎没有必要,而且倒排索引本身就是一种压缩方式,这点和LZ4一样,都是基于字典技术,处理重复文本的压缩,但是 Lucene还是有针对term在存储时进行压缩的。 而且在 tim 文件中,为了构建Lucene的高性能查询数据结构(即FST), term在存储时就是按字典排序存储的,这也适合压缩。
但是,目前已知的无损压缩对于非常随机的字符串压缩效果都不好,lz4亦然,笔者曾测试过80万次随机541字节长的字符串的文本(413MB)压缩,tar/gzip基本上是压缩后稳定在263MB左右,LZ4 则在413MB,比原文件大了1KB左右。
不过如果文本是80万次重复530字节长的字符串时,tar/zip基本上是400MB压缩后稳定在1.7MB左右,而LZ4也可压缩到1.7MB。深入展开需要了解压缩“Compress”这门技术了,google以及一些研究机构也在此付出巨大努力,Netflix曾经爆款剧《硅谷》就是以主角 Richard发明神奇压缩算法Pied Piper展开,笔者最早接触还是WinRAR/Winzip之类,这里附上一个有意思的知乎链接世界上最大的文件压缩率是多少,不过不建议大家尝试里面的解压炸弹(decompression bomb)。
需要指出的是上述80万次重复文本 LZ4 压缩效果要看 LZ4设置的block size,1K时压缩到160MB,16K时压缩到12MB,512K时才压缩到1.8MB,16MB时压缩到1.2MB,而ES基于Lucene使用LZ4时block size 是16KB,也就是官方推荐,默认可以装进L1 cache的配置,即考虑性能优先,而不是压缩比,所以对于超大文本的压缩不要过于指望压缩效果。
因为 deflate压缩性能比lz4差许多,对于写多情况也不建议 BEST_COMPRESSION,理论上至少会导致写入性能下降,至于读性能则还需要考虑磁盘读写,所以作这个测试需要考虑到,虽然官方推荐在Tune for disk usage可以考虑,但是在对存储要求时才考虑,对于小文本没有必要选择最优压缩。
如上面两点提到的,我们看下ES字段存储,还记得ES 5之后字段都会有一个.keyword字段吗,上文图片可以看到,即不分词的索引,同时还默认开启 _all,_all 字段索引就是包含全部字段的内容索引,也即上文图片所述 _all,他们都会写入Lucene的 xx.keyword或_all字段,所以对于启用 _all 的索引排除某字段后,几乎是相当于排除三份针对该字段索引的字节数,而msg文本也是比较随机的,压缩不好占空间,这也是为什么 上文中禁用 msg 索引后,该index的存储文件从310G降到了110G。
最后,如果对ES写入Lucene的这段代码感兴趣,可以从 ES 的 org.elasticsearch.index.engine.InternalEngine看起,ES对于索引的CRUD操作等接口都是通过InternalEngine实现的,相关追溯在 IndexResult index(Index index)方法。
Ref
Apache Lucene - Index File Formats
Elasticsearch Tune for disk usage
Luke, the Lucene Toolbox Project + Swing
Lucene FST