intro1:常见hash函数及使用场景
intro2: Java hashCode实现相关/为何计算hash时选择31/33相乘
intro3: Redis哈希表装载因子为何大于1,而非Java的0.75
intro4: 新hashmap实现为何要8个冲突才升级红黑树
intro5: 一致性哈希是否真的有用
在写前一篇博文时,发现Redis上的一个hash函数相关的commit:Use SipHash,于是笔者想到总结下开发中经常遇到的哈希函数,本篇为第一部分,介绍常见hash算法、java 的hash应用,以及hash对应的数据结构在Java/Redis使用,后续介绍广义的hash,如GeoHash,LSH的Simhash/minHash,以及笔者曾在比较相近图片时用到的hash,同GeoHash还会介绍下Google S2/Uber H3编码。
什么是Hash函数
说到哈希函数,大家最熟悉的就是MD5,早期下载工具甚至附带md5校验,那么他具体是什么呢?
我们看wikipedia上一个非数学的版本的解释
散列函数(Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。好的散列函数在输入域中很少出现散列冲突。在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
Hash function推荐译为散列函数,其本质是一种单向散列函数(one-way hash function),从上述定义看到,好的散列函数通常具备几个特点:
- 单向性(One-way)
输出确定,且无法逆推出源数据。这也是单向散列函数定义 - 抗冲突性(Collision-resistant)
要求产生2个相同的散列值是概率低,即对任意两个不同的x,y,使得h(x)=h(y)是困难的。 - 雪崩效应(Avalanche effect)
即映射分布均匀性和差分分布均匀性,或者说 原始输入数据的微小改动,能导致散列值差异非常大
当然最好能具有快速计算的特性,除此以外,信息安全领域中的Hash算法可能还有其他要求。
Hash函数应用领域
散列函数是一类函数,更是一种思想,它常被一些语言用来实现一种数据结构(Hash表、Hash Table、散列表),也广泛用于密码学。
我们看下一些教材对其使用概括:
1, 在数据结构中的应用
使用Hash算法的数据结构叫做哈希表,也叫散列表,主要是为了提高查询的效率。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数就是hash函数,存放记录的数组叫做哈希表。在数据结构中应用时,有时需要较高的运算速度而弱化考虑抗碰撞性,可以使用自己构建的哈希函数。
2, 在密码学领域的应用
在密码学中,Hash算法的作用主要是用于消息摘要和签名,换句话说,它主要用于对整个消息的完整性进行校验。比如一些登陆网站并不会直接明文存储用户密码,存储的是经过hash处理的密码的摘要(hash值),当用户登录时只需要对比输入明文的摘要与数据库存储的摘要是否相同;即使黑客入侵或者维护人员访问数据库也无法获取用户的密码明文,大大提高了安全性。
大部分语言的标准库都会提供一种散列表(HashTale/HashMap/Dict等)的数据结构,该数据结构采用空间换时间的思想,做到插入和查询都是O(1)的时间耗费。
像Java中一切皆对象,对象本身自带hashCode属性(即散列值), 散列函数就是生成唯一标识的工具。
作为数据结构场景下,hash函数的选择会侧重于散列值均匀分布或者足够随机的特性,生成唯一标识就考虑抗碰撞特性,而密码学中因为考虑到完整性,增加破解难度,就要优先考虑抗碰撞性,如MD系/SHA系。
作为数据结构
和Hash函数对应的数据结构就是HashTable/HashMap/Dict等键值映射表,不同语言不同称呼,本文统称HahsTable。此类Hash函数目标就是把n个元素塞到m个槽位里面(通常假设n < m), Knuth在 TAOCP 里举例,散列函数可有m^n中函数(结果),但仅有m!/(m-n)!是无冲突的,也即该情况下避免冲突的函数是通常极少的,比如知名的“生日悖论”。
计算Hash方法
算法导论里给出两种方法
- 除法散列法
hash函数为 h(k) = k mod m, m最好为质数,避免整数幂次,比如当m为2的整数次幂32时,那么k仅有低5位参与散列,上文提及的雪崩效应就不符合了。 - 乘法散列法
hash函数是 h(k) = m(kA mod 1)
即:用关键字k乘以常数A(0<A<1),提取KA的小数部分(kA mod 1),用m乘以这个值并取整。
Knuth TAOCP里提到A为黄金分割数最优。 - 全域hash
1 | hash函数为: h[a](k) = sum{ai*ki|i =0,1,...,m-1}mod m |
解决hash冲突方法有开放地址方法、链地址法、建立公共溢出区、再哈希法等,其中开放地址策略又可再分线性探测、再平方探测、伪随机探测等,上述均可在数据结构书找到不详述。
Java的HashMap、Redis的dict(hashTable)就是链地址法,《算法导论》中分析了对于采用链表式的简单一致hash表,一次成功/不成功的查找耗时均为 O(1+a),其中a=n/m,a为装载因子,也就是Java HashMap的loadfactor,简单一致表示这n个元素存入m个表槽时的概率是相等的,这点也是容易理解的,关于这个结论的应用下文还会提及。
常见Hash
General Purpose Hash Function Algorithms,这里列举早期常见c实现的hash函数,RS、JS、PJW、ELF、BKDR、SDBM、DJB、DEK、AP等,不过有些依旧常用,像DJB Hash,Daniel J. Bernstein提出,在php/apache/perl/redis中都有使用,页面提到的设计hash思想以及hansh分类等都比较清晰。
doobs hash,这里作者测试/点评了一些流行的hash,如Lookup3、OneAtATime、SpookyHash、FNV Hash
CRC32、MurmurHash、Goulburn、DJB、MD4等。
这里Which hashing algorithm is best for uniqueness and speed是其他测试,作者测试了DJB2、DJB2a、FNV-1、FNV-1a、SDBM、CRC32、Murmur2(32b)、SuperFastHash。
上述hash基本上都注重两点:快速、低碰撞。包括像把hash结果作为变量参与下一轮hash就是为了制造雪崩效应。
DJB hash就是最快速并且较均匀hash,也曾是流行。不过MurmurHash算法后来居上,在上述几个测试中几乎都是最快的,官方评测是FNV/SuperFastHash等的2-3倍,由Austin Appleby提出,最开始是作为SMHasher测试hash套件一部分,Austin后入职Google,2011年发布其变种 CityHash算法,性能快于MurmurHash,后者目前似乎无Java版。2014年,google发布farmHash,继承CityHash增加其他平台支持。
Nginx的在ngx_http_split_clients_module中split_clients指令,即常用来做负载/分离测试(AB)的,就采用MurmurHash,Redis HLL实现也用到了MurmurHash,Cassandra默认基于MurmurHash分区,HBase也提供此分区方法。
上述hash算法目的都是快速和抗碰撞,此外还有一类hash侧重快速和随机性,就是Siphash: SipHash is a family of pseudorandom functions (a.k.a. keyed hash functions) optimized for speed on short messages,即面向短文本的侧重随机效果的,与其说是hash,不如说是随机函数。目的即是用来防止 哈希洪水攻击(hash-flooding DoS attacks),如官网介绍,已经被OpenSSL/Python/Rust/Wireguard/xBSD/JRuby/Perl/OpenDNS等内置应用。
Redis之前提供了三种计算哈希值的函数,对应分别为:dictIntHashFunction即Thomas Wang’s 32 bit Mix Function,dictGenHashFunction 即 MurmurHash2, dictGenCaseHashFunction 即djb hash,默认murmur2,不过Redis 从4.0后开始抛弃了并删除上述代码了Switch hash function to SipHash. #718 code,下文也会提到。
MurMurHash也是支持随机的,只需提供一个seed的参数产生一个随机的MurMurHash函数,这样每次初始化后,hash值会不同,可以防止dos。但一般默认是0(Guava即是0),确保同一段字节hash结果始终一样。
需要指出的是
1)当hash的字符串位数不多或者作用域小数据量时时,DJB /RS/JS等hash可能比MurmurHash快。
2)上述BKDR采用质数31/131其实接近java String采用hash算法。
3)上述都不能用于下文密码部分hash函数,抗碰撞弱于MD。
4)像有的hash如FNV,选择32位内最大的素数 16777619 ,因为低位1较多也可有不错效果,不过如果没有右移操作,高位似乎可能因为溢出而始终无法参与hash了。
为什么hash常对 33/31 取模
作为整数,20世纪100以内自然数33和42曾在很长一段时间内无法找到表示为三个立方数和的解一度成为神秘数字,这里33似乎也有一些与众不同,上述的DJB Hash 也叫 Time 33 hash,time 33就是乘33的意思
1 | unsigned int DJBHash(const char* str, unsigned int length){ |
((hash << 5) + hash) 就是位操作实现的hash * 32+hash,即 hash * 33。
使用33是作者做过hash测试效果得到,我们这里看国内的1-1000之间作为乘数的测试,链接:为什么Java String哈希乘数为31,作者测试结果证实mod偶数或20以内的数据冲突率都很高,作者测试里四个数据效果:
1 | 31、33的冲突率分别为0.13%、0.14%,执行耗时分别为10、11,实时基本相当 |
编程规范牛书K&R’s book 作者Kernighan 和 Ritchie 在《The C Programming Language》提出BKDR Hash,采用/* 31 131 1313 13131 131313 etc.. */ 作为种子计算hash,Joshua Bloch的 Effective Java就提到java选择31,效果好,而且可优化。
Java Hash
上面谈到Java String的hashCode实现,这里谈谈java其他hash
HashTable
Java中Hashtable就是使用除法散列法,Hashtable的table.size默认是11,即默认 % 11,resize时元素数量*2+1,但是初始size可以为指定值,也即指定初始2幂次时,hashtable可能散列的效果不好。
顺便提一下Netty中的IntObjectMap采用的是开放地址寻址法,hash策略就是简单的 key ^ (capacity - 1),capacity是2的幂次。
Object.hashCode
HashMap/HashTable等都需要其hashCode方法,并且有一套hashcode/equals 规范,那么未重写时,即java Object默认hashCode方法怎么实现的呢,是内存地址的十六进制表示吗?
这篇文章How does the default hashCode() work里作者追踪源码并探讨几点,源码里多可见,笔者摘录下。
Object.hashCode是native方法,调用如下
1 | // src/share/vm/prims/jvm.cpp |
上述get_next_hash 提供了随机数、自增sequence、1、内存地址、Marsaglia’s xor-shift scheme with thread-specific state,默认就是 第五类实现,即含线程级别初始状态的hash码,可以看到 _hashStateX 就是一个os::random()的随机数,其他参数是恒定值,这也意味着Object.hashCode默认是随机的,也即如果你未重写hashCode,那么这个类即便每个属性都是一样的值,jvm重启之后/甚至在两个线程里new的两个对象,他们各自的hashCode是很可能不等的。
java Doc里
1 | Whenever it is invoked on the same object more than once during an \ |
也提到了 during an execution of a Java application,即保证执行期间不变,没有明确指是始终不变,很多人忽略这点。
需要指出的是:
1) 上述,对象在调用一次hashCode之后,其hashCode缓存在其对象头字段里,以便之后使用,即mark->hash()。
2)通过jvm参数,-XX:hashCode=4 可以指定hashcode生成策略为内存地址。
但是为何hashcode默认要随机数?
让我们看一段历史,虽然二者不一定相关。
如果你使用Python 3.2以上,那么shell里运行hash(‘www’)后退出再运行 hash(‘www’),就会发现两次hash值不一样,这是为了解决python Hash Dos问题,具体参考:PEP 456 – Secure and interchangeable hash algorithm,文末链接是各语言。
这个问题曾经在PHP服务较明显,而Tomcat/jettty等也出现过,笔者刚工作时就曾经历过Tomcat因此升级,这里是讨论:Apache Tomcat and the hashtable collision DoS vulnerability,tomcat CVE-2011-4858,java hash dos,原理就是已知tomcat这些通过hashmap解析用户post的参数(request.getparameter),那么用户会构造一个表单,比如含有一万个字段,他们都会hash到同一个键上,即查询时退化为链表查询了,导致在处理上比较损耗CPU,这点据说对PHP服务影响巨大,CPU观测到飙升。Tomcat该CVE解决就是设置参数限制用户的表单字段数量。
需要指出的是,除了Object.hashCode,JDK 1.7(应该是2012年2月之后的版本,早期1.7版本是没有的)的HashMap似乎也做了改进,在计算HashMap的加入了hashSeed随机,hashSeed会在vm启动时通过random初始化,而对于String类sun.misc.Hashing.stringHash32则采用 murmur3_32,该murmur算法使用时间戳作为随机种子。
1 | final int hash(Object k) { |
Java HashMap
不过,随机hash可能不符合部分人的理念,JDK 8中HashMap就去掉了随机hash,String的hashcode永远一样,链表解决冲突改为红黑树,避免hash攻击。
所以HashMap的hash策略相比1.7就简略许多:
1 | static final int hash(Object key) { |
1.7中String类曾使用murmurhash计算hashcode,其他则会对其进行20/12/7/4位的rotate,1.8中这些都不存在了,并且只一次性rotate16位,这样保证高低16位均可再次参与hash,如果论1.8的放大效应应该不如1.7,但是大大减少了rotate和异或操作次数,而且有红黑树兜底冲突。
在计算hash这步应该会快些,但1.8中红黑树带来代码复杂性,且当该槽退化为红黑树后,转换为treenode时,进行查找比较时,对于”class C implements Comparable
正是由于这一点,JDK 1.8 的hash关于红黑树其实是两个改进:1)当槽位冲突超过8(含)时链表升级为红黑树,2)resize后,如果槽位冲突小于6,但是红黑树,此时会降级为链表。
上面其实也意味着当hashmap size较小如64,1.8中参与有效hash的位通常不如1.7的多。
为何是超8个才升级为红黑树
备注里写的清楚了
1 | * Because TreeNodes are about twice the size of regular nodes, |
笔者不会涉及红黑实现细节,只讨论部分问题。
上述可知:
1, TreeNodes 重量级,耗费空间
2,hash冲突超过8个的情况概率可以做到非常小到6/10^8机会,
也就是说,该版本里JDK设计者并不希望用户的hashmap出现红黑树!
引入红黑树冲突解决是作为极端情况(DOS)下的兜底方案,而不是一种对Hashmap自身功能上的优化,笔者不确定1.8的HashMap是否比1.7快(单线程),虽然hash变得简单高效,但本身操作就足够敏感,相信科学的压测结果未必能足够证明二者性能之间的差异(如hash的key为String时,string的长度影响get的性能)。不过,笔者可以确认的是,“Java 8 引入红黑树处理冲突提升了HashMap的性能”,这种说法是完全不对的,Java 8 HahsMap即便性能有提升也不会直接和链表冲突变为红黑树相关。
正如作者在上述写的选择8的原因是因为这样使得链表升级TreeNode情况的可能性足够小,这里又怎么去考虑性能呢,更别说链表超过8个转换为树是否更高效了。
至于loadfactor为0.75纯粹是经验值(可能就是0.5和1.0取中间),没有什么好探讨的,笔者的疑惑是“Ideally, under random hashCodes, the frequency of nodes in bins follows”,毕竟下文得出选用8作为临界的原因就是“出现K次同一个碰撞”符合泊松分布,但首先确定的一点是作者的公式前提是假设loadfactor为0.5,如果强行认为泊松分布没有问题,但是需要解释lambda为何0.5。
如果按注释理解,笔者猜测作者可能是把K数丢到N桶作为二项分布,或者说作者可能是把N个桶作为一个个的单位时间,而把数丢到N桶看成是每个时间内概率性到达一个数,这个概率是0.5,当把时间无限长,显然这个模型里每个时间K次到达本身就是泊松分布,把lambda带入0.5就得到作者的 (exp(-0.5)*pow(0.5, k)/factorial(k))结果了。
换句话说,将n/2的数随机放入n个桶内,约0.60653066的的量是空桶,0.30326533的量含有1个,0.07581633的量含有2个…这个结果有点意外,但是如果代码试验记录函数关系,猜测可能是符合这个图形的(文末笔者用Redis测试了一下,结果是比较符合这个结论的)。
为何hash槽数是2的幂次
不同于hashtable,hashmap的槽数始终是2的幂次,Redis也是如此。
读者可能已经知道HashMap采用这种设计,主要是为了高效取模(tab[i = (n - 1) & hash])和扩容时计算简单,但是前文除法散列法有介绍到”取模应该避免2的幂次来避免高位就不参与运算“,这是否矛盾?
笔者认为有缺陷但不矛盾,首先 取模前的 hash值有做过高低位的一次位操作,并且在此之前也有几轮位散列,这个过程比较接近 乘法散列法,只是此时m为2的幂次的倒数。
loadfactor 0.75 是否合理
笔者认为合理,但是有时候可以不遵守。
loadfactor是衡量hash表饱和度的指数,过大也意味着hash冲突的概率很大,当超过0.75时,HashMap进行扩容(resize),槽数翻倍,读者可能已经在Java doc中看到推荐0.75,以及其他博客里认为的超过0.75性能就有损耗,不推荐。
而Java中,hashmap要素就是希望冲突尽量少,将表操作维持在 O(1)时间,但是,超过0.75时性能损耗有多少呢?
上文我们分析了采用链表式的简单一致hash表,理论上一次成功/不成功的查找耗时均为 O(1+a),a为装载因子,也就是说,loadfactor设为3的时候查询性能是之前的2.9倍,但考虑到hash操作可能是耗时重点,这个值会比2.9小。
笔者没有进行严格的JMH测试,分别用0.75和4作为loadfactor插入12万条KV数据对后,简单的进行16轮get测试,在笔者的mac电脑上时间比在1.4-2.8之间,但是占用空间4是32768条,0.75是262144条,仅为其1/8。
对于内存消耗频繁/GC频繁的应用来说,如果能接受hashmap的查询耗时损耗,笔者认为这可能是非常值得的。
当然,上述还有待笔者更多的性能测试数据,简单的循环跑可能有干扰。
Redis的loadfactor、hash相关
Redis本身有Hash类型的数据结构之外,redis数据库实现也是一个Hash表,即dict,存储了redis所有的KV对,其哈希策略早期是随机的murmur2,后来或许是受SipHash作者的murmur存在hash DOS问题,策略改为SipHash了。
dict用链表解决哈希冲突,其loadfactor默认大于1才开始resize(dict_can_resize固定1),可以一直持续增加到5后再强行resize(dict_force_resize_ratio固定5)。
即redis认为自己的数据量大于dict的槽数是允许的,而Java HashMap建议槽数大于数据量。
当然Redis Hash也得益于其hashtable不仅可以扩张,而且可收缩,支持一种渐进式rehash机制,即其hashtable逻辑上有两个hashtable组成(当rehash时),可同时并用,并且空闲时迁移,直到rehash结束后,其中一个清空。
可以看到一个redisDb就是一个dict,dict主要就是dictht ht[2],2个大的hash表(dictEntry)引用,
1 | /* Redis database representation. There are multiple databases identified |
4.0后,redis大部分dictType的hashFunction都是dictSdsHash(部分dictObjHash),他们都属于dictGenHashFunction,即对应siphash实现。
Redis的HyperLogLog目前还是用MurmurHahs进行哈希。
我们知道Antirez老版本性能报告里,redis get操作大概在12万/s左右,那么Redis的dict查找性能有多快呢?验证需要深入代码,不过我们可以看另一个数据,就是pipeline测试,redis-benchmark -n 1000000 -t set,get -P 64 -q ,在笔者电脑上get操作可以达到约120万,表示redis的dict类查询至少120万的,当然这和单线程 hashmap get操作可达千万级别(key为1-6长度字符串)有点差距,不过确实提供了一个load factor 大于1的场景。
Redis resize过程还有许多内容,比如scan的实现,能看到作者是非常的善于用心,不走寻常路思维,不过本文不进一步讨论。
关于一致性hash
什么是一致性hash呢?看看wikipedia上的定义:
Consistent hashing is a special kind of hashing such that when a hash table is resized, only keys need to be remapped on average, where is the number of keys, and is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.
这里是笔者网上摘录的一段翻译:
一致性hash是一种特殊的hash,当hash表的大小发生变化时,平均只有K/N个key需要重新计算映射关系(rehash),这里K是hash表中key的数目,N是hash表中槽位的数目。相比之下,大多数传统的hash表实现,当hash表的大小发生变化时,几乎所有的key都需要重新映射,这是因为key和hash表槽位之间的映射是通过取模预算实现的。
如果是纯粹的理解一致性hash,那么这个概念/算法 实在是太容易理解了,甚至不能称作是算法,笔者也不会放一张经典的一致性hsh轮状图。
简单理解就是hash失败时找临近的节点,增加虚拟节点通常是为了希望hash分布均匀,当然带来好处是hash仅跟虚拟节点有关,如加路由等功能操作时hash算法只需关心虚拟节点不用关心机器。
需要注意的是,Redis本身是没有一致性hash概念的,官方Redis集群cluster,也没有用到一致性hash相关的技术,redis和一致性hash没有直接关系,“redis一致性hash算法/原理”这种说法完全不对的,混淆redis和一致性hash关系可能是第三方带来的,比如Jedis/Twemproxy。
像Twemproxy假设某节点故障后恢复,期间因为一致性hash关系写到其他机器上的数据实际上就浪费了,这不是理想的使用redis方式,除非你只是把redis作为缓存使用,并且支持重载缓存。
Jedis里有一致性hash概念,并且实现了一致性hash算法,但是如果你只想把jedis作为操作redis的工具的话,那么一致性哈希实在是一个bug。
因为,真实环境里,大多数Redis会借助集群技术(但不管如何,数据冗余是必须的)来实现数据不丢失,至少不是出现一致性hash期待的某节点增删。
这种一致性hash是没有必要的,大部分存储服务集群的”client“这一端只有分片概念和服务一致的分片(路由)策略足矣。
当然,一致性hash算法不是没有用,像Jedis在Sentinel模式下,用来定位存储节点(分片)时,其“hash”功能还是有作用的,但“一致性”功能是多余的。
像官方标准的集群实现Redis Cluster,其实现就直接采用slot的概念,对Key用CRC16定位slot(HASH_SLOT = CRC16(key) mod 16384),而jedis 也提供了支持Redis Cluster的实现,在BinaryJedisCluster中封装带有重试机制的JedisClusterCommand,代理给JedisSlotBasedConnectionHandler执行, 其代码里的getConnectionFromSlot即是从缓存中获取对应的JedisPool,即一个Jedis连接执行命令。
虽然redis cluster设计/代码初期被吐槽过,但笔者认为目前实现要比其他更接近分布式,可能和其他相比或多或少存在集群的命令支持度问题以及自身实现的限制,不过正确的方向比一切重要,而且现在redis cluster已稳定发布,大量被使用,就笔者所知有些大公司依旧是Codis、Tweamproxy、Sentinel之类的方式,毕竟迁移到Redis Cluster模式不是无缝的,存在风险,大部分技术人员不动。不过笔者也知几家大公司线上服务在用Redis Cluster。
作为密码学
该类hash具有上文提到的单向函数特性,即其是一种消息摘要算法,而非加密算法,这类散列函数通常称为密码散列函数(Cryptographic hash function,否则就是non-Cryptographic的),它适用于检测消息的完整性,确保消息没有被篡改,该类散列函数的散列结果通常是一段定长的字节(如128-512不等)。
最常见就是数字签名、消息认证(fingerprint/message digest),像数字指纹、电子签名、SSL公钥认证、资源授权等都会用到,这属于深奥的HMAC内容;也可用于 登录认证,即常见的口令加密,计算密码和随机盐的散列值保存,避免明文密码;Token,即一次性授权,过期等失效;另外,生成伪随机数也是常见应用,Java的Sun公司早前推出的SecureRandom类就是自称SHA-1的伪随机数生成器。
总之,密码学本身涉及广泛,足够花上几辈子研究,这里仅是作为hash函数介绍下,入个门,也不能算是窥豹一斑,这也印证了笛卡尔圆理论。
只要知道UUID、CSRF Token、Jwt Token、remeber me token、防重放、密钥、区块链等场景都会用到。
常见的散列算法
常见的散列算法有:CRC-32、MD5、SHA-1,SM3,以及广泛使用 SHA-2(SHA-224、SHA-356、SHA-384、SHA-512)和海绵结构的SHA-3(Keccak 算法),像AES/DES/RSA则是加解密算法不算散列函数。
为什么会有这么多种类呢或者命名呢?
其中 CRC-32 循环冗余校验最早,1961年提出,不过其主要用来进行错误检测,可以有限纠错/奇偶校验等,常用于数据存储和数据通讯,硬件支持,Hadoop就实现了高性能的CRC-32算法作为文件的Checksum保存。可用于密码学领域的Cryptographic hash function,较早的是MD系列,1992年,在经历MD2、MD4几个消息摘要算法版本迭代后,Ronald Linn Rivest向IETF提交了MD5。
SHA(Secure Hash Algorithm,安全散列算法)家族的算法,由美国国家安全局(NSA)所设计,并由美国国家标准与技术研究院(NIST)发布,是美国的政府标准,1993年的SHA-0版本,但发布之后很快就被NSA撤回,是SHA-1的前身。SHA-1则于1995年发布,SHA-1在许多安全协议中广为使用,包括TLS和SSL、PGP、SSH、S/MIME和IPsec,曾被视为是MD5(更早之前被广为使用的散列函数)的后继者。
其中SHA-0/1和MD5类似,1996年Hans Dobbertin就指出存在散列碰撞的可能性,只是密码专家们一直无法给出实际例子,或者说这个穷举计算耗时太久,但2004年王小云及其研究同事展示了几个1024-bit消息的MD5第一个碰撞示例,一年后王小云与姚期智夫妇提出新的SHA-1散列函数散列冲撞算法,碰撞缩短为2^63步。
SHA-2:2001年发布,包括SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256 六个不同的算法标准。
SHA-3:2015年正式发布,并未大规模应用,因为目前 SHA-2 尚未被有效破解,但是和MD/SHA-0/1一样,存在破解可能,所以IETF寻找一种新的架构,于是有了基于Keccak,海绵结构(sponge construction)的SHA-3,这也是NIST于2005年/2006年响应自MD5和SHA-1被破解之后召开会议讨论制定新的Hash函数标准。
SM3:中华人民共和国政府采用的一种密码散列函数标准,由国家密码管理局于2010年12月17日发布,其安全性及效率与SHA-256相当,也是王小云教授主导设计的。
严格来说MD5/SHA-1现在应该是该淘汰的,比如很多下载网站已经不建议MD5,像Apache下载提供的是SHA512,即SHA-2系列验证,md5比如作为nginx etag(当然性能考虑默认似乎是modify time+file size)/加盐的密码验证等。
下面一张表看清SHA家族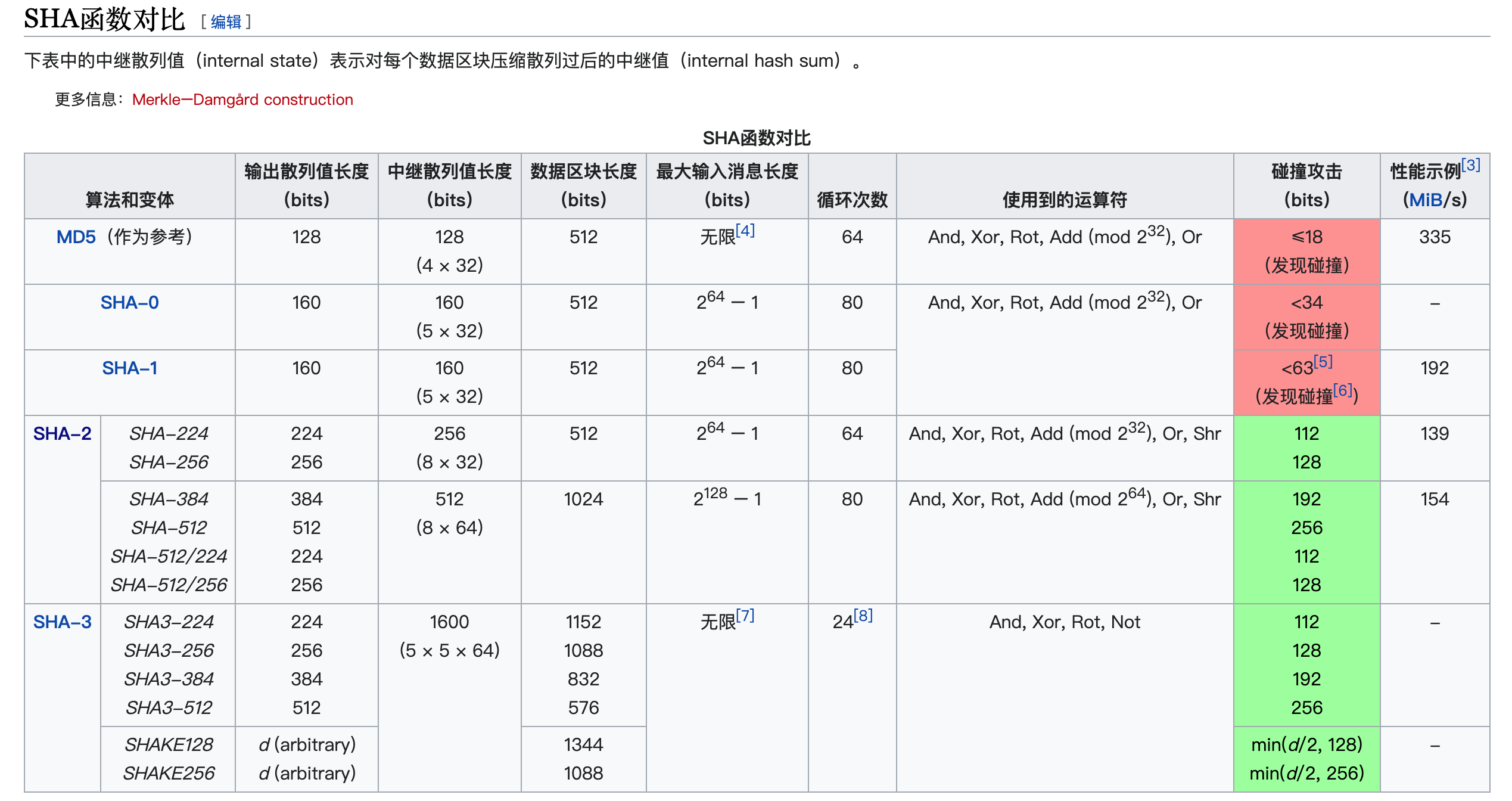
MD5碰撞
上述,在 How to Break MD5 and Other Hash Functions 这篇文章里,其实提供了一种碰撞MD5的方法,理解本文需要一定的密码学和数理知识,不过看起来是基于古老而又大胆创新的差分攻击思路(比前人胜在数学专业),作者通过设计一些列约束条件,成功控制长比特进位的攻击路线 ,但碰撞产生的差分以及对应差分路径和条件影响碰撞对的搜索,在 HashClash作者Marc Steven提出构造前缀碰撞法,并提供了一个伪造ca证书的示例,作者还开源了自己的 Chosen-prefix Collisions for MD5 碰撞实现,感兴趣可以到这里下载,可以自己尝试一个MD5碰撞,不过看起来是基于Windows平台的,而且会比较耗时。
构造前缀碰撞可以在尾部添加不同的填充数据是的恶意程序能够伪装,但其实还有一个比较有趣的应用,笔者知道JPG类图片天然适合在尾部隐藏数据,所以虽然两张不同的图片MD5一样的概率几乎为零,但是借助填充,理论上也可以构造一个MD5碰撞,他们MD5一样,但是是两张完全不同的图片,博主Nat McHugh 就提供了一个方法,链接在这里(需要梯子) ,图片一张是船,一张是飞机。
有趣的另一点是,如果有时间,你可以拿上述两张图,对比下微博/各种云/推特等他们的图片上传策略,是否基于MD5。
相似Hash
上文是两张不同图片同样Hahs结果,如果两张图片是同一张,但有细微差别,如混入填充数据,有办法hash结果也类似吗?
自然想到SimHash,但是效果如何,后续提及。
彩虹表(Rainbow table)
相比目前大多构造MD5碰撞耗费算力,MD5碰撞另一个方案是彩虹表。
国内一些提供md5破解网站可能如宣称基于KV存储,当然可能也会增加一些常见的缓存,如e10adc3949ba59abbe56e057f20f883e 就可以立即返回 123,不过笔者尝试解密md5大多不成功。
但彩虹表不是简单的像一些认为的基于“密文->明文+”的存储,解密md5的时候通过密文直接反查出明文,wikipedia的解释:
A rainbow table is a precomputed table for reversing cryptographic hash functions, usually for cracking password hashes. Tables are usually used in recovering a password (or credit card numbers, etc.) up to a certain length consisting of a limited set of characters. It is a practical example of a space–time tradeoff, using less computer processing time and more storage than a brute-force attack which calculates a hash on every attempt, but more processing time and less storage than a simple lookup table with one entry per hash. Use of a key derivation function that employs a salt makes this attack infeasible.
这里官方提供的常用已生成好的List of Rainbow Tables,上述预先计算好的表指的就是基于 多少位密码、何种字符集(数字/字母)、哈希链长度、条数、第几次等生成的速查表,常常用于破解长度固定且包含的字符范围固定的密码,以空间换时间的典型实践,比暴力破解(Brute force)更实用。
预计算
我们可以参考下 预先计算的散列链 ,即 如 faster time-memory trade-off technique 介绍,RT的设计思路是很值得花时间理解,它本身考虑的是函数散列值和散列条件之间域的映射,除了构造 R函数(reduction function,归约函数)和哈希函数H之外,它并不关心hash函数具体实现,其把所有Hash运算看作是Hash链上一段,这也使得该理念适用大多数的散列函数,只要根据初始条件生成足够数量的链(预计算表),每次R/H运算后查找是否存在hash链,如存在,则重复哈希链的计算过程并chck前置是否符合,否则重复R/H计算至选定次数(k-1),大幅降低表的数量(实际上,当K=1时,正是全量的“密文->明文”对),但缺点寻找过程需要计算,生成预计算表耗时,而且该表覆盖可能不够全面导致查询失败(概率可通过预计算条件计算)。
通过使用增加R/H的中间态,大幅减少数据的存储,限定条件(比如8位字母+数字,99%概率),可以计算得比全量存储小多了,可能几百千万级别的。
拓展
Merkle-Damgard结构,其是一种较早且常见的构建防冲突加密散列函数的方法/架构,他是上文提到SHA-3以外的Cryptographic hash function存在的理论支撑,1979年Ralph Merkle和Ivan Damgård独立证明了在添加合适填充和compression function具备防碰撞的情况下,那么对应的Hash function也是(collision-resistant)防碰撞的。但其本身存在缺点,催生了后来的海绵体(sponge construction)计划取代。
其他
生日悖论
指在不少于23个人中至少有两人生日相同的概率大于50%。此非悖论,只是30年代悖论未确立,但该结论有违大多数人直觉,比如在60个人的班级里,存在生日相同的概率就达99.4%了。
识别“篡改”,但是无法辨别出“伪装”
单向散列函数能够辨别出“篡改”,但是无法辨别出“伪装”。鉴于此,提出了消息认证的技术,包括消息验证码和数字签名。
长度扩展攻击(Length extension attacks)
是指针对某些允许包含额外信息的加密散列函数的攻击手段。
盐, salt
加盐可以防御彩虹攻击,因为彩虹表生效前提是静态的hash函数。
bcrypt是根据Blowfish加密算法所设计的密码散列函数,其提供一个加盐的流程以防御彩虹表攻击。Blowfish和AES/DES一样都是加密函数,像Java就有BCrypt工具类实现各种hash以及加随机的盐,如Spring Security实现BCryptPasswordEncoder类,支持加盐的密码认证,其会获取到保存的初始盐和hash,并进行比对。
Bloom Filter
BF本质是一种bit数组的数据结构和hash函数,用于判断一个元素是否属于这个集合,他能确认否定的结论,不能确认肯定结论,即BF未命中即表示不属于,反之未必。
BF准确度和bit位数和函数次数相关,不过前提是函数设置比特位随机独立,像guava则直接用murmur3_128得到一个数组后,以低64位为初始值,每次加上高64位 来确定本次bit位置1.
BF只能增不能删除数据,不过存在其他一类Counting BF,有限度的支持删除。
HyperLogLog Counting
HLL 是基数计数Cardinality Estimation一种,即常用来统计不同元素的个数,如uv、不同的uid、不同的ip等,HLL本质是一种基数估算。
和BF一样,其实他们都是用hash函数来模拟随机性。
redis hashtable的KV分布的问题
笔者用Redis模拟,并非Java,分别用随机产生53万/105万万数据测试下来接近备注里的分布。注意:
1)在插入完成后,需要等几秒redis完成rehash再debug htstats。
2)下述随机数的数量选择在2的幂次附近,是为了让redis进行rehash临界,满足 0.5的负载,比如产生106万是为了近可能未产生超1048576个从而使得redis rehash。
1 | # 产生529276个随机数/1048576个槽 |
可以看到当负载因子接近0.5时,上述分布和java HashMap给出的理论分布比较符合的。
REF:
散列函数
SHA家族
哈希碰撞与生日攻击
Merkle–Damgård construction
不安全的随机数
MD5碰撞的演化之路
Denial of service via hash collisions