intro1:JPG文件生成/压缩原理
intro2: 对离散余弦变换在图片压缩应用的思考
intro3: JPG文件存储格式
intro4: aHash/dHash/pHash原理及源码介绍
intro5: 对aHash/dHash/pHash准确度、局限、场景等思考
前一篇文章介绍Simhash/Minhash等,下面来看下之前留下的图片的相似性度量算法:ahash、dHash、pHash,在笔者经历的图片/PDf上传的经历中,上述方法效果不错。
本文主要以JPEG格式为例探索下图像几种哈希算法,不过图像的处理并非本文要介绍重点,只是为了方便下文理解,如果你只对怎么寻找近似图片感兴趣或看这里感到不适,可以跳过本节。
先简介下图片的组成便于下文理解。
JPG 是什么
wikipedia定义:
JPEG是联合图象专家组(Joint Picture Expert Group)的英文缩写,是国际标准化组织(ISO)和CCITT联合制定的静态图象的压缩编码标准
我们通常说的JPG/JPEG实际指的是JPEG格式的文件,其解码/编码部分是遵循JPEG标准。在下一段会介绍JPEG具体存储格式。
如果没有JPG,图片原始存储/表示格式会是什么样子?我们知道记录和显示彩色图像常用RGB方法表示,一般RGB表示是一个四字节int(如java/python中的pixel值是int),所以比如笔者手机中一张4k*3k像素的图片需要的空间就会是4k*3k*4=48MB。
而RGB存储表示的长度可能会不同,如图片原始Raw格式由厂家支持度每像素8bit-24bit略有不同。像RGB555用16bit即RGB分量都用5位,RGB24用24bit即RGB分量都用8位,RGB32用32bit即RGB分量都用8位剩下的8位用作Alpha通道或者不用。同样上图在相机存储占用48MB字节,实际相机raw图片可能略小于此。
这不利于传输和存储,尤其是在早期存储和带宽较贵时。所以想到了压缩,当我们用基于Lz77之类的无损压缩保存为png或者tiff等格式时可能8-24MB(笔者手机该图jpg反解存png是19MB)之间。无损压缩本身存在极限尤其是jpg这样没有固定重复模式可循时。那么是否存在一种有损压缩更好的压缩比同时保持图片清晰度?有损压缩JPEG就能做到压缩后远小于48MB,在笔者手机是3.4MB,而JPG处理减少近似度时可以达2.5MB且看不出和原图区别。
JPEG2000是JPG的下一代版,支持有损和无损压缩,且压缩比更高,其基于小波变换的压缩标准比基于离散余弦变换的JPEG标准不会产生的块状模糊瑕疵,不过核心算法存在版权和专利的风险并未得到广泛支持。
JPG压缩步骤:
JPG主要利用两点假设即相邻的像素信息(亮度/色度等)是相近的,这些块的信息可以合并即渐变的颜色被转换为一块块的颜色而不影响显示效果,另一点基于图像信号的频谱特性进行滤波,利用人视觉系统误差过滤高频频谱。
先看通常步骤,这里主要引用自wikipedia JPEG:
1)RGB转YUV:
什么是以及为什么要转YUV呢?
YUV wikipedia:
YUV,是一种颜色编码方法。常使用在各个影像处理组件中。 YUV在对照片或影片编码时,考虑到人类的感知能力,允许降低色度的带宽。
YUV是编译true-color颜色空间(color space)的种类,Y’UV, YUV, YCbCr,YPbPr等专有名词都可以称为YUV,彼此有重叠。“Y”表示明亮度(Luminance、Luma),“U”和“V”则是色度、浓度(Chrominance、Chroma)。
从历史的演变来说,其中YUV和Y’UV通常用来编码电视的模拟信号,而YCbCr则是用来描述数字的影像信号,适合影片与图片压缩以及传输,例如MPEG、JPEG。 但在现今,YUV通常已经在电脑系统上广泛使用。
YUV通常分为平面格式和紧缩格式(packed formats)
即YUV不仅是编码RGB色彩方法,还支持降低色度的带宽实现压缩,即紧缩格式。
RGB转YUV其实是有精度损失的,因为需要double浮点数转整数,只不过小数损失忽略故在有些文章里认为这步无损。
也就是实际上我们说的黑白电视上的影响或者黑白照片其实不是黑白图像,而是灰度(gray)图像,YUV中Y按该式计算Y = 0.299 * R + 0.587 * G + 0.114 * B,这就是一些灰软件度化(gray)图片时常用的设置像素点颜色转换式子(其取均值或仅Green不常见),而我们说的黑白二值图片是像素值只能取255(8位)或0的图片。
下面图左边是灰度图片,中间是使用了Floyd-Steinberg抖动算法实现的黑白二值图像,失真较小,最右是暴力的大于某值则白否则黑的黑白图片(可看到其比中间图失真较大)
2)YUV色彩抽样(YCbCr 4:2:0)
即利用视觉因素对YUV的进行采样来达到压缩目的,实现色度和浓度的压缩,即上文Packed formats。因采样原因,这里是有损的。
3)离散余弦变换(DCT)
在YUV转换后就可以将图片按8*8像素的单元格分割(不足则补充),对每个单元格减去128(便于值域对称、归零)再进行DCT。DCT本身是无损的,但如果你的处理矩阵始终是int则可能存在强转的误差。
图片点阵表示是一个二维矩阵,所以对应二维傅立叶变换,这步可简单的认为是将原矩阵变换为新的矩阵,新矩阵支持逆矩阵恢复,只不过新矩阵将高低频分离,适合下一步量化并便于压缩。
4)量化(Quantization)
在DCT变换后,对于亮度量化表和色度量化表来说(具体实现不同可能来自同一矩阵),低频区系数较大分布左上方,而人眼识别不敏感的高频区的系数较小分布右下,如何合理的舍弃高频区数据(并保证低频区不致误差)的过程称为量化。
通常提供量化表做除法取整,不同的图片质量对应不同级别量化表(也影响压缩比)。
5)熵编码(entropy coding)
这一步主要包括Zigzag编码和Huffman编码。
为什么叫熵编码呢?因为Huffman和Zigzag编码过程中不丢失任何信息,这和图像本身的图像熵不同概念,不过上文对空间冗余度的压缩倒是符合压缩熵小(虽然熵小不一定无用)的理念。
Zigzag编码即是从左上角之字形扫描(在编码解码实现上直接用查表法即可),这么做使得相近的值排列一起便于编码
上述即是JPG图片压缩过程,至于存储过程可参考下文“JPG 存储格式”,即将上述几个步骤得到的元数据结合标记字段按JPG格式存储即可。在解码JPG时,则按照JPG存储格式和标记字段解析出元数据,之后对元数据按上述5步进行逆操作即得到JPG图片点阵图,感兴趣下文“Java里的JPG”提供代码可参考。
JPG压缩的思考
为什么需要离散余弦变换(DCT)
本文不会涉及傅立叶公式,仅是原理讨论,但提供几个链接可入门。
我们知道作为一种数学上的积分变换,满足一定条件,傅立叶变换(Fourier transform,简称 FT)特殊的地方在于无论多么复杂的函数都可以表示成正弦基函数的线性组合或者积分,是不是有种“描述困难,傅立叶变换”的感觉,最初提出时认为是任何周期函数,后经修正为满足狄利克雷条件,在工程领域FT影响更深远。
傅立叶变换就可以用来做信号在时域(或空域)和频域之间的变换。
先看几个概念:
1)图像高频分量:图像突变部分;在某些情况下指图像边缘信息,某些情况 下指噪声,更多是两者的混合;
2)低频分量:图像变化平缓的部分,也就是图像轮廓信息
3)高通滤波器:让图像使低频分量抑制,高频分量通过
4)低通滤波器:与高通相反,让图像使高频分量抑制,低频分量通过
还有一个是图片的 空间冗余度,即图片相邻个点通常是相近的(渐变/变化缓慢),即像素点取值相同,这种空间相关性就叫 空间冗余度(声音/视频也有该特性)。
人眼看到图片就是一种采样,人类视觉听觉都有限,比如低于20赫兹大于2万赫兹人耳都听不到,同样的微小变化人耳大多听不出来,就是傅立叶变换一套理论在JPG(图片)/mp3(音频)/H.264(视频)中都有用武之地,两个系统之间信号传递可接受的采样误差。
我们常见的图是位图,也叫点阵图或绘制图,不像矢量图/SVG可以用一种语言或公式描述来达到“压缩”目的,即便简单到全黑的位图也只能依赖点阵(矩阵)来表示。但如果我们把图片像素值表示为数字,以上述Y为例,图片看成一个平面,一系列的离散的像素点灰度值看成是二维平面上的连续信号上的点,即把图像看作是一个二维函数f(x,y),其值为该点灰度 。图像灰度的变化速度(梯度)对应空域灰度变化程度,上文图像平缓部分决定图像轮廓,即低频分量决定信号的轮廓,如果以频域角度看,叫做图像信号的能量主要集中在低频附近。图像的边缘部分变化梯度大,即映射到频域上属于高频分量,描述局部特征,但是这种变化可以一定程度的失真(图像的边缘检测在其他地方反而是重要的,比如视觉检测时描述物体),而使人观察不到明显差异。傅立叶变换就提供了这样的功能,能将原图分为基底低频高频波,这也是傅立叶牛的地方,把时域信号转化为频域的若干频率分量的叠加,对于有限域的离散信号适合用离散傅里叶变换(DFT),但DFT运算量/时间复杂度大,所以又有快速离散傅里叶变换算法(FFT),至于推导高数2里可见,不过超出笔者记忆所以不详述。对于图像/音频等类信号处理时,实偶函数的傅里叶变换可转化为只含实的余弦项(笔者也在探索中…),因此构造了一种实数域的变换——离散余弦变换(DCT),总之使用DCT不仅使得计算简单,而且使图片的能量更加几种,这篇课件Discrete Cosine Transform 有对DCT详细讨论。
这里用该课件图描述下JPG压缩。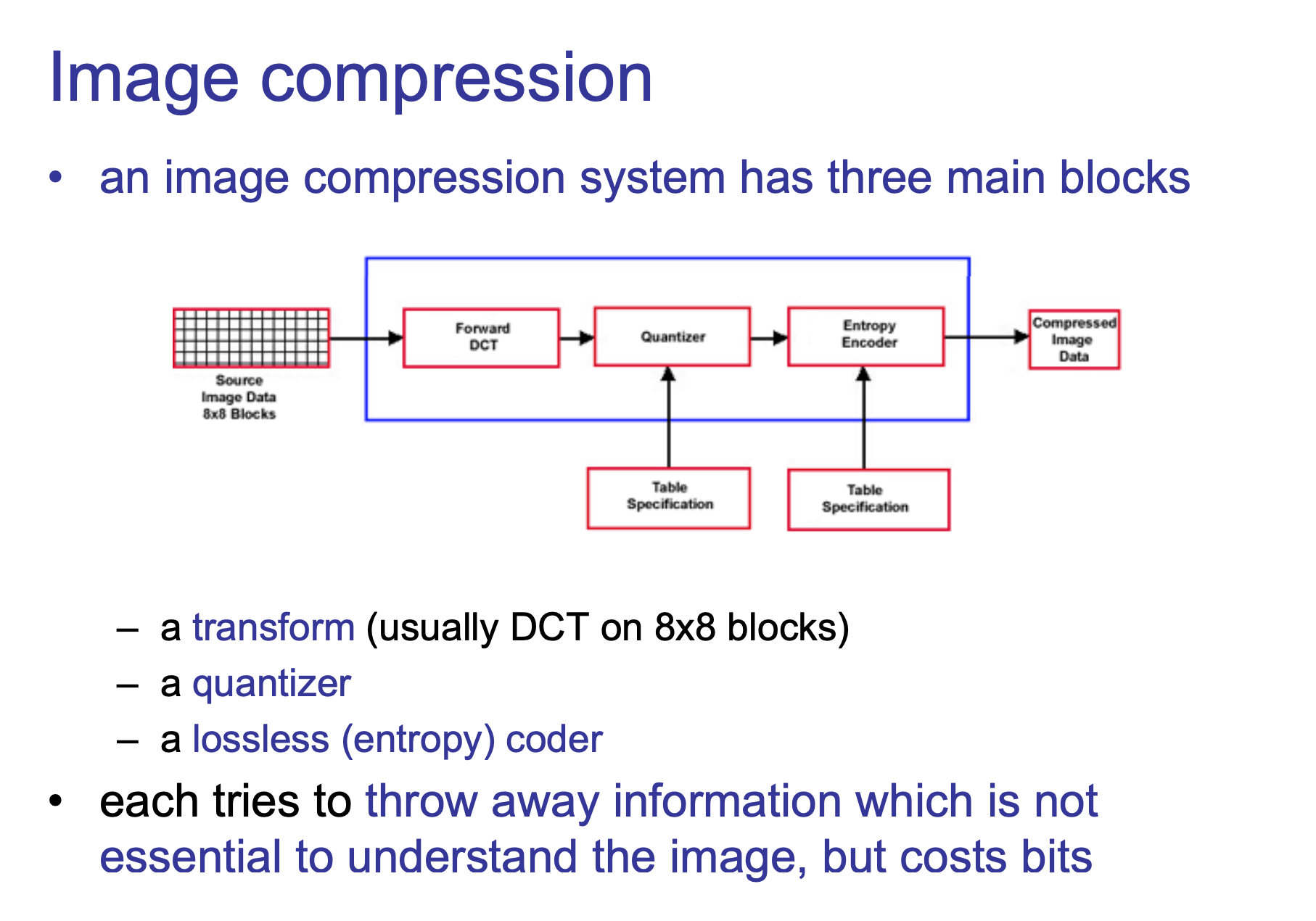
需要指出的是对图像进行低通滤波就可以得到图像的轮廓组成即图像本身(同时体积缩小),只是边缘的清晰度会衰减(设置阈值能使人眼很难观察到),对其高通滤波能得到图片的边缘但内容丢失,这个链接里作者附图解释较明了。
类傅立叶变换使可逆的,即DCT逆变换(IDCT)可将图像的频率分布函数变换为灰度分布函数。
为什么分割成8*8
其实只是经验值而已,大则降低质量小则降低压缩比,但如果是超大像素图或超高DPI屏幕16*16分割未尝不可。
DCT表示
举一个简单的例子,这是笔者通过matplotlib对一张全白(RGB均为255)的图片的dct矩阵的图示: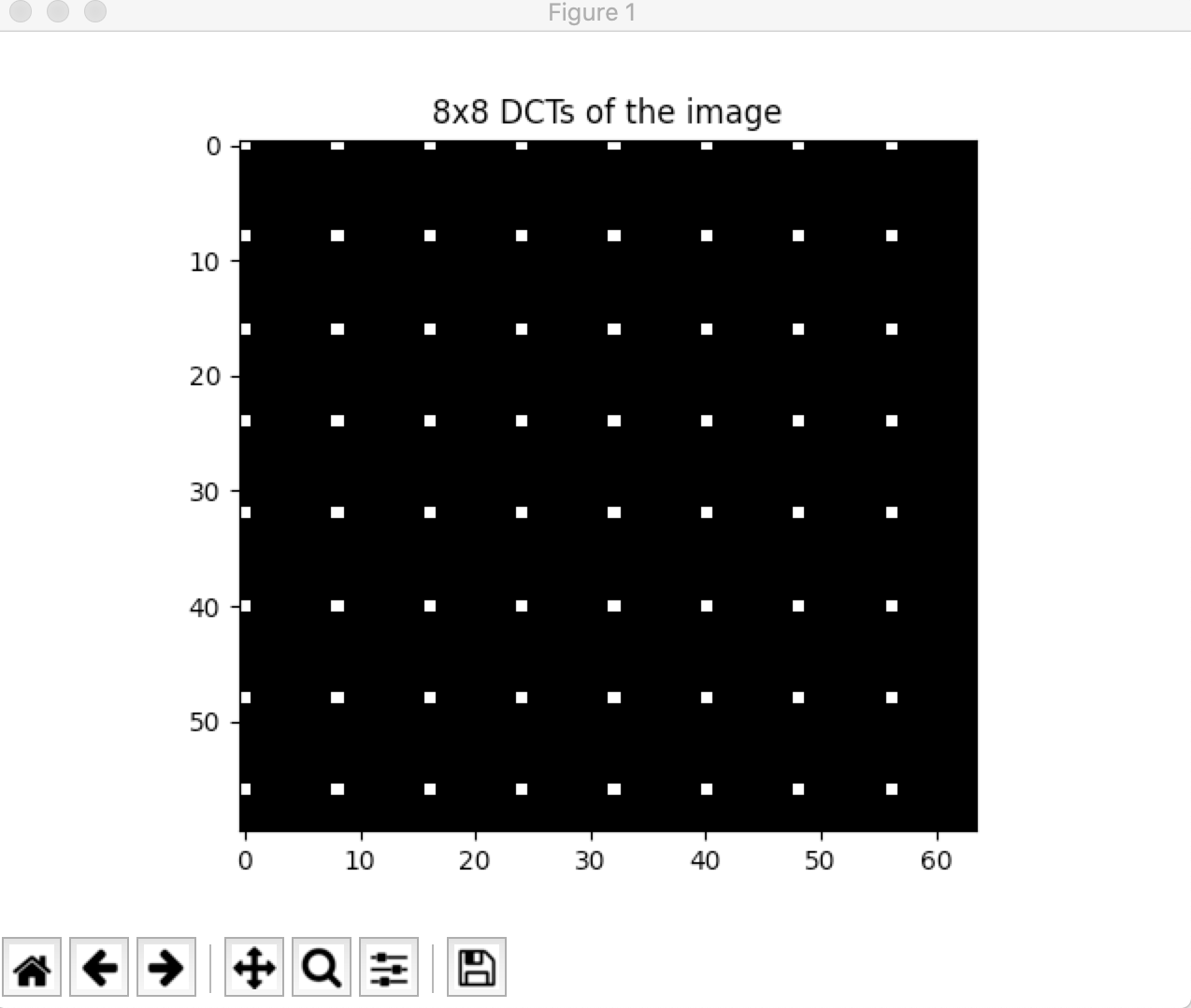
上图是未gray过的,如果gray过则根据转换式应该是近蓝色而非近白色。我们可认为有用的信息只是其中白色块,即白色块通过IDCT即可恢复全白图,可以简单认为Huffman压缩只需针对这些白色块进行压缩保存。
标准量化表
在上述量化这一步时,离不开量化表,量化表本身是个矩阵即量化矩阵,DCT得到的矩阵除以该矩阵在进行round取整操作,可以使得高频位尽可能的变成0,也减少非零系数幅度,即量化矩阵决定图像的质量。
量化矩阵是写入DQT的,比如下面看起来质量精度还是比较高的。
1 | ➜ imagehash hexdump gen1.jpg |
至于该矩阵如何得来笔者并未找到相关信息,不过libjpg提供了相关的计算方法,JPEG标准矩阵,1-100图像质量级别矩阵的计算jcpparam.c。
下图分别是JPEG标准. p147 推荐亮度和色彩常用的量化表,分别表示保留50%的图像质量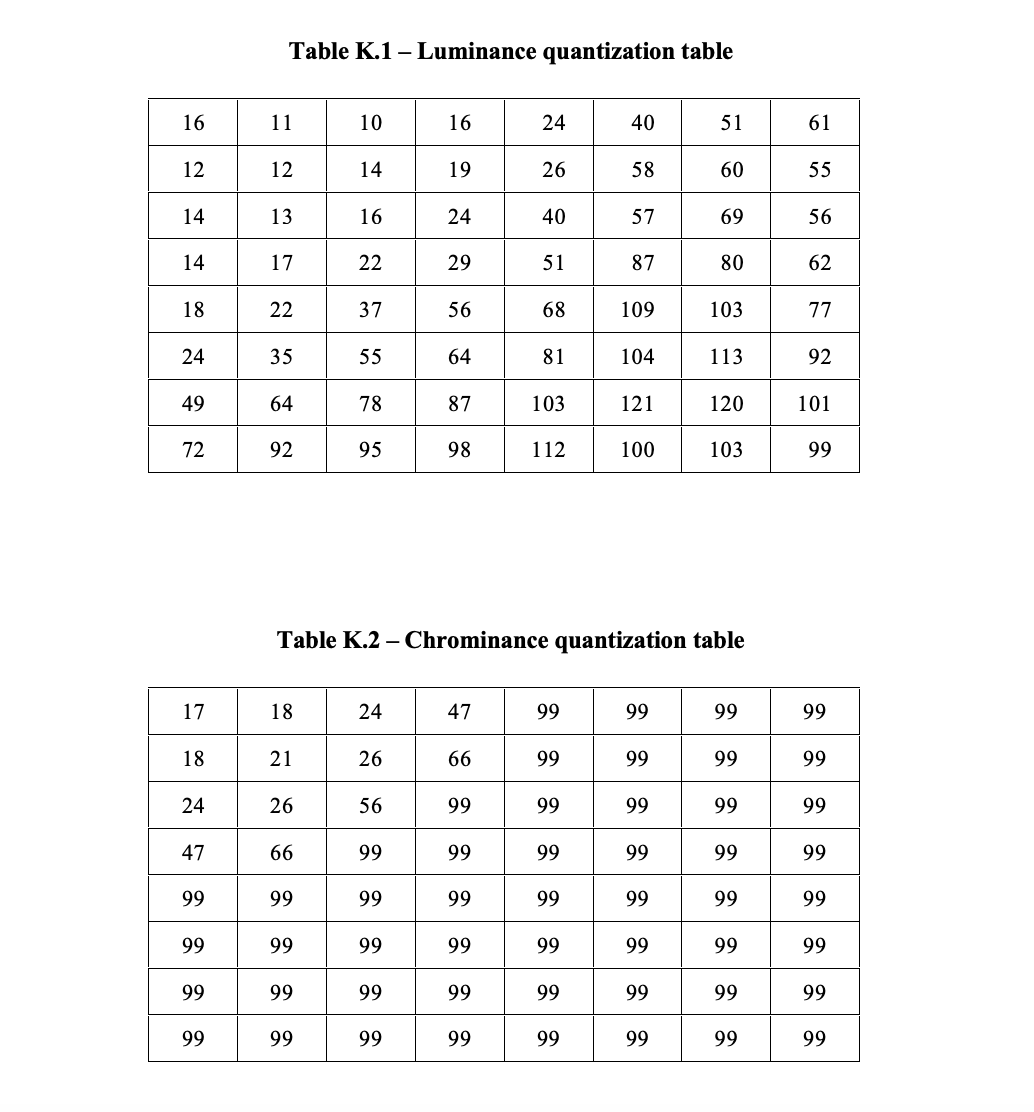
JPEG Compression Quality from Quantization Tables 这个页面包含JPEG标准量化表,同时更列举常见相机的量化表,该网站也包含常见相机JPG图片质量比较。
matplotlib一个示例
通常借助Matlab只需几行代码可清晰理解,如果无Matlab可尝试下python的matplotlib和numpy的DCT操作图片,可以参考下这个链接:JPEG DCT Demo
,不过或许是matplotlib版本问题(py 3.7.2),代码想要跑通有几处要修正:
1 | # import要加入这两行 |
图片压缩方法不仅仅局限于傅立叶变换,比如基于矩阵奇异值分解也是一种方法,这篇文章图示了1-128级别基于SVD的图片压缩效果。这可能也是大多数人容易理解的方法。
Android JPG往事
JPG图片网络传输,只要是正确无差的传输是不会画质逐渐变差的,但是如果你上传过程中有哪一步对jpg图片再次进行压缩或过滤高频或色彩压缩或色彩处理之类的操作,画质就会逐渐变得模糊,常用的聊天工具传输前就可能对图片有损压缩(各自均有算法并生成好的压缩,但慎重)。Android图片处理库曾经在将高精度的RGB色彩转换为低精度的YUV(8位)存在bug导致色彩误差产生色彩偏绿。
这个网站可以体验下JPEGreen。
JPG 存储格式
JPG格式就是包含了离散余弦变换(DCT)后的频域滤波有损压缩再Huffman无损压缩的图片格式,所以JPG并不是通常理解的像素存储,而是有特定格式的。
JPEG/JFIF是最普遍的被用来存储和传输照片的格式,JPG文件具体是怎么存储的或哪些格式呢?存储JPEG文件格式叫标准叫JIF(JPEG Interchange Format),最早的实现是JFIF(JPEG File Interchange Format),这也是被广泛使用的,之后是Exif(Exchangeable image file format) ,两种标准虽然不兼容,但是大同小异。我们看JFIF文件格式:
其中附加Marker一般是:DQT、SOF、DHT、DRI、COM等。
下面就是常见JPEG Marker及含义,wikipedia上可看到
| Marker名称 | Markerflag | 说明 |
|---|---|---|
| SOI | 0xFFD8 | Start Of Image |
| SOF0 | 0xFFC0 | Start Of Frame 0 |
| SOF2 | 0xFFC2 | Start of Frame 2 |
| DHT | 0xFFC4 | Define Huffman Table(s) |
| DQT | 0xFFDB | Define Quantization Table(s) |
| DRI | 0xFFDD | Define Restart Interval |
| SOS | 0xFFDA | Start of Scan |
| RST0~RST7 | 0xFFD0 ~ 0xFFD7 | Restart |
| APP0~APP15 | 0xFFE0 ~ 0xFFEF | Application-sepcific |
| COM | 0xFFFE | Comment |
| EOI | 0xFFD9 | End of Image |
| JPEG Marker含义就是表示一种叫做标记段的数据结构:JPEG Marker + Detail Data,marker就是上述 0xFFxx之类字节,detail data中两个字节表示长度,剩余表示具体数据。 | ||
| Marker中,SOI表示开始,EOI表示文件结束,之后的数据不会被认为是JPEG文件,除了APP0之外其他APPx是可选的,DHT表示Huffman表,RST用于复位表示,DQT表示量化表生成YUV数据,中间comprssed image。 data表示真是的zigzag编码的DCT系数矩阵。 | ||
| 如果了解更多可以参考中文这里:JPEG文件格式解析(一) Exif 与 JFIF,jpeg图片格式详解 | ||
| wikipedia 文件格式参考 JFIF,JPP文件处理参考 JPEG,后者清晰的讨论格式和组成以及格式和编码之间的协作,原文还图示了DCT对JPG图片的影响,值得一看。 | ||
| 同编辑软件同质量DQT大多数相同,甚至Huffman数据同,如笔者对Mac编辑的两张32*32像素的笑脸图字节码比较,两张笑脸仅有嘴角上下角度不同,可看到只有压缩数据部分不同。 |
JPG隐藏数据
如果你仔细看上文是否想到对图片进行隐藏数据的原理?比较常见的是我们生成图片时可以添加APPx(其他格式图片也有类似元信息)信息从而加入自己的数据,像Mac截图图片会默认添加Screenshot/adobe之类信息, Preview改动图片保存是就能看到 Photoshop3.0.8BIM字样,上图可见。但这些信息长度应该不超过两个字节长度,com似乎也可以隐藏,这类属于基于文件结构的图片隐写。
其次就是比较常见的附加式的图片隐写,正如上文提到JPG的EOI表示文件结束,之后数据不会参与图片的运算(其他格式类似)。
但上述第一种可能会被图片处理软件篡改忽略,后一种面对图片处理时则可能会被直接截断忽略。
我们还可以基于LSB原理的图片隐写,利用了人类对颜色变化不敏感的特性,通常RGB有256级变化,于是低位(比如低2位)造成的误差可以忽略,就可以用来用来存储隐藏的数据。LSB可以很好的隐藏数据,但其实信息隐藏能力受限原始图片,且低位过多是隐藏图片容易被发现,低位过少则可能无法隐藏,可以测试这个pthon实现的基于LSB隐藏 lsb-steganography,pip安装PIL就可以运行了,代码仅一个py文件还是非常清晰简单的。用1bit隐藏时图片还是很模糊的。
LSB不仅可用于无损压缩如PNG/BMP之类的图片,也可用于JPG,原理和PNG类似,不同是虽然jpg本身是有损压缩,但仅是对于边界有损较明显,但LSB理论上的确会对隐藏图片有损,不过DCT变换更能使得原图不那么容易被发觉是其长处(但该工具可以)。
还记得之前阿里巴巴曾经有过图片加水印事件吗,这里的水印不是普通观者可见的,而是盲水印,通过扩频技术掺杂在图片数据本身里的,该水印混杂原图特征(频域)里,可能也是抗干扰的,除非原图改变足够大否则总可以解码水印,当然这里是猜测,具体需要待验证。如果感兴趣可以参考:
Misc总结—-隐写术之图片隐写, 深入理解JPEG图像格式Jphide隐写,LSB图片隐写
Java里的JPG
Sun/Open JDK和Android底层应该默认都是libjpeg 实现jpeg解码/编码等操作,这在其awt文件夹(share/native/sun/awt/image)下可见,
如自称比libjpeg快的高性能实现 libjpeg-turbo,或者纯java实现的支持多种图片格式的 Apache Commons-imaging,后者是一个纯Java实现的多种格式图片解码,其中即可看到JPG解码组件。
需要指出有损压缩不仅上述,比如google基于JPG的Guetzli压缩据说更巧妙利用其视觉模型决定丢弃那些细节增强压缩比。还有适合视频流的jpg压缩,及基于深度神经网络等。
图片哈希算法
上面介绍了些图片处理知识,那么理解aHash/pHash/dHash应该会容易些。
对图片哈希为什么不直接用MD5呢?如前一篇文章提到,笔者曾参与的项目不仅期望同样的图片和pdf/ppt文件可以秒传,这样好处是上传体验快,而且节省cdn费用,同时对于服务来说,节省了去图片转pdf以及解析pdf/图片文字的时间和cpu。最初版本使用了md5计算,但后来出现内容基本完全一样由不同人上传的pdf/图片,区别仅是格式变动或加了水印或软件加了meta信息等,这些是md5粗暴编码不能解决的,那时候开源里还没有tensflow以及类似,只搜到了叫skLearn的python工具,不过文档较少。笔者想起了曾经选修过的图像处理课程,所以了解到aHash、pHash等这些基于LSH的算法,能基于图片的内容进行相似度编码。
这里来看下这三种编码强大之处,主要基于wikipedia/python imagehash/图像相似度中的Hash算法。
aHash(平均哈希算法)
三种算法都需要对图片进行缩小,默认生成64bit指纹,图片缩小一般基于插值算法,由于是缩放长宽像素统一,所以还是可以对应原图的,但缩放损失图片细节,尤易对基于均值的哈希aHash精度影响,不过这个概率其实并不大,下文链接测试数据也反应这点。
图片就是二维空间上的像素值分布,aHash的均值就是计算像素的平均值,上文知灰度图即是图像的特征,所以aHash步骤一般是:
- 缩放图片
将图片缩小为8*8像素图,得到64个像素点。 - 转灰度图
如上文YUV所述是一种灰度方案 - 算像素均值
计算灰度图8*8的矩阵中所有元素的平均值,假设其值为avg - 据像素均值计算指纹
初始化ahash为空字符串,按左上到右下顺序遍历G每像素,如果G(i,j) >= avg,则ahash += “1”,否则ahash += “0”
上述即可得到图片的aHash的编码,相似度比较采用就是前一篇文章提到的海明距离,下面p/dHash都是采用海明距离比较,距离满足 “0: particular like; < 5: very like; > 10:different picture”。
pHash(感知哈希算法)
上文我们知道DCT(未量化的)是一张图片的特征,pHash就是利用这个特性,一般步骤:
- 缩放图片
将图片缩小为32*32像素图,得到1024个像素点。 - 转灰度图
同aHash - 计算DCT
DCT后得到对应的32*32的数据矩阵 - 缩小DCT
取上一步得到32*32数据矩阵左上角8*8子区域,上文知这里能量最集中 - 算平均值
计算上一步8*8的矩阵中所有元素的平均值,假设其值为avg - 计算指纹
初始化phash为空字符串,按左上到右下顺序遍历G每像素,如果G(i,j) >= avg,则phash += “1”,否则phash += “0”
距离比较同aHash。
dHash(差异哈希算法)
上文提到图片的梯度概念,dHash就是对梯度的均值比较,一般步骤:
- 缩放图片
将图片缩小为9*8像素图,得到72个像素点。 - 转灰度图
同aHash - 算差异值
从第二行开始,当前行像素值减去前一行像素值,得到一个8*8矩阵G - 计算指纹
初始化dhash为空字符串,按左上到右下顺序遍历G每像素,如果G(i,j) >= 0,则phash += “1”,否则phash += “0”
距离比较同aHash。
ImageHash
这里贴下imaghash的上述三个实现的代码,因为代码看起来太精简明了了,注释已删掉,完整代码见链接。
1 | def average_hash(image, hash_size=8, mean=numpy.mean): |
a/d/pHash思考
1)上述精准理论上 aHash < dHash < pHash,但是pHash耗时远大于a/dHash,而dHash则是在精确度和性能之间均衡版。
2)图片稍微旋转就会影响a/p/dHash的效果,即其不能处理旋转过的图,但我们也可以分别旋转90/180/270度,多计算三次,这样可处理常见的90/180/270度旋转情况。
3)构造一个相同a/d/pHash不同内容图是是远比MD5容易的,比如中间态(缩略图)即是,笔者并不清楚深度学习图片修复原理,不过前几天看新闻现在修复技术能通过32*32像素的图片生成大图:高糊图片可以做什么?Goodfellow等人用它生成一组合理图像(至于是否改变a/p/dHash值需要笔者再了解下),但像 ahash/dhash我们也可以根据中间产生的8*8、8*9矩阵,然后构造一张8*8图片,并维持均数逐层放大32*32,128*128等,只不过最后得到的图片不忍卒看罢了。
4)笔者未找到aHash/pHash的证明,不过官方网站提供了一些效果数据:Design & Validation,以及pdf文档:Implementation and Benchmarking of Perceptual Image Hash Functions,可以说是pHash的论文,提到设计思路和效果数据,并对比了其他变换对pHash影响,以及如dHash等效果比较。Perceptual Multimedia Hashing。
5)上文提到a/p/d精准度,这里是关于dHash/aHash/pHash各自的讨论,Kind of Like That,可以看到作者使用15万张图片测试,aHash产生a huge number of false positives,大量的假阳,pHash则是 No false positives,但是耗时是aHash的2倍,dHash则Very few false positives,和aHash同样快。
评论里也有各类python/java/.NET/php等实现对a/d/phash的效果对比,很值得一读,另外这篇blog还是蛮有趣的,通过图片识别一些假新闻。
6)上述链接可见,因为精度/性能表现皆优,作者推荐先用dHash计算,排除大部分不相似,如果要解决 false positives,可以再进一步使用pHash。
7)a/p/dHash适合小图片,对于超大图精度可能会损失较多。
8)大图/小图 pHash一致,所以最好过滤下小图。灰度图像和原图也可能一致,如果你不希望上传灰度图时显示彩色,那么可以先判断下是否灰度图片。
9)这里附上一个相似图片搜索,存储图片 pHash以及查询时使用fuzzy query即编辑距离小于2,Similar image search by pHash distance in Elasticsearch,纯粹基于图片相似,或许实用性不够好,但是是一个高效的思路。
其他
前文文本相似指的是字面上的相近,而不是语义上的相似,像腾讯/百度均有段文本相似的接口可参考,举个例子,比如短文本相似度,可以判定”小儿腹泻偏方”和”宝宝拉肚子偏方”0.90的相似度,但和”小儿感冒偏方”只0.74的相似度,如果用莱文斯坦距离后者就比前者相近了。
参考:
wikipedia JPEG
Discrete_cosine_transform
PNG文件格式详解
为什么图片反复压缩后会普遍会变绿而不是其他颜色
JPEG文件格式解析(一) Exif 与JFIF
图像相似度中的Hash算法
hackerfactor Looks-Like-It
四种计算文本相似度的方法对比
NLP 点滴 :文本相似度 (下)
** 遵循CC协议,转载请标注来源 **